RETHINKING THE VALUE OF NETWORK PRUNING
ICLIR 2019, Berkeley
https://arxiv.org/abs/1810.05270
Rethinking the Value of Network Pruning
Network pruning is widely used for reducing the heavy inference cost of deep models in low-resource settings. A typical pruning algorithm is a three-stage pipeline, i.e., training (a large model), pruning and fine-tuning. During pruning, according to a cer
arxiv.org
Abstract
Network pruning은 inference cost를 줄이기 위해 많이 사용하며, 보편적인 pruning algorithm은 3개의 stage로 구성된다.
- training
- pruning
- fine-tuning
하지만, structured pruning algorithm을 사용하는 대부분의 SOTA들이, random initialize한 모델을 학습하는 것보다 성능이 낮은 경우가 많았다.
1) training a large, over-parameterized model은 최종적인 모델을 얻기에 항상 필요한 것이 아니라는 점과
2) large model의 중요한 weights 역시 small pruned model에 유용하지 않으며
3) large model로부터 받은 weights보다, architecture가 더 중요하고, 이는 pruning이 아닌 architecture search로 대체할 수 있다.
그렇기에, 향후 structured pruning methods 연구에서는 baseline evaluation을 더 신중하게 해야한다.
또한 "Lottery Ticket Hypothesis (2019 ICLR) "와 비교하였는데, optimal learning rate에서 "winning ticket" initialization은 random initialization을 이기지 못함을 발견했다.
Introduction
A typical procedure of network pruning consists of three stages:
보편적인 network pruning은 3가지 stage로 구성된다.
- train a large, over-parameterized model (sometimes there are pretrained models available)
- prune the trained large according to a certain criterion
- fine-tune the pruned model to regain the lost performance

위 과정에 대해 일반적으로 두 개의 믿음이 있다.
- over-parameterized network가 중요하다.
- 그래서 몇몇의 baseline에서는 scratch부터 학습한 것을 설정하기도 했다.
- pruned architecture, weights는 효율적인 모델을 얻기 위한 필수 과정이다.
- 대부분의 pruning 기술에서는 scratch부터 학습하는 것이 아닌, finetune하는 것을 더 선택했다.
이 논문에서는 structured pruning methods(conv channel or layer단위의 prune)에서 위의 믿음이 정답이 아님을 보였다.

- structured pruning methods에서 predefined target network architectures는 random init으로 학습한 작은 model보다 성능이 낮았다.
- structured pruning methods에서 automatic target network architectures는 random init으로 학습하면, finetuning보다 더 좋은 성능을 보였다.
- architecture를 얻는 것이 더 중요하지, weight를 보존하는 것은 크게 상관 없다는 것을 의미했다.
Unstructured pruning method에서는 작은 dataset에 한하여 scartch부터 학습한 모델의 성능보다 prune+finetune의 성능이 약간 더 높았지만, large-scale dataset에서는 성능이 낮았다.
만약 pretrained large model이 이미 있다면, prune and finetune으로 효율적인 아키텍쳐 모델을 만드는데 필요한 training 시간을 아낄 수 있다.
pruning과정에서 해당 weight가 중요하다고 판단했어도, pruned model을 local minimum에 가둘 수 있다.
automatic structured pruning algorithms은 중요한 weight를 찾는 것 보다 효율적인 architecture를 탐색할 수 있다.
Methodology
pruned model을 scratch부터 얼마나 학습하는 것이 좋은가? large model과 prune model을 같은 epoch로 학습시키는 것은, computation cost가 다르기에 적합하지 않다. 그렇기에 FLOPs를 사용하여, 비슷하게 맞췄다.
Scratch-E는 small pruned model을 large model과 동일한 epoch로 학습한 것
Scratch-B는 small pruned model을 large model과 동일한 연산량으로 학습한 것
predefined structured pruning
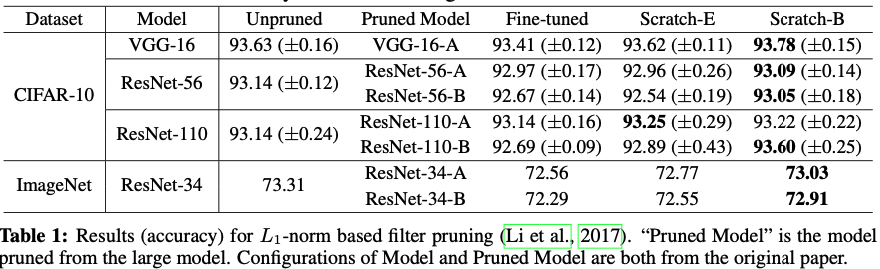
$L1\,-norm$ pruning이고, Pruned Model은 predefined target model이다.
scratch부터 학습한 모델이 fine-tuned 모델과 거의 비슷한 수준의 정확도를 보이는 것을 알 수 있다.
Scratch-B가 대부분의 경우에서 Scratch-E보다 좋은 성능을 보였다.
automatic structured pruning

scratch부터 학습한 small model은 fine-tuned model에 거의 근접했음을 볼 수 있다.
Scratch-B는 10개중 8개 실험에서 fine-tuned model을 넘었다.