https://arxiv.org/abs/2208.05117
https://github.com/TaesikGong/NOTE
GitHub - TaesikGong/NOTE: The official PyTorch Implementation of "NOTE: Robust Continual Test-time Adaptation Against Temporal C
The official PyTorch Implementation of "NOTE: Robust Continual Test-time Adaptation Against Temporal Correlation (NeurIPS '22)" - GitHub - TaesikGong/NOTE: The official PyTorch Implem...
github.com
KAIST논문
완벽하게 이해하고 정리하지 못했다.
(언젠가 TTA를 다시 하면 다시 보는걸로..)
Abstract
기존 TTA는 test sample들이 independent하고 identically distributed (non-i.i.d) 됐다고 가정했었다.
실제 application에서는 그렇지 않다는 것이 저자들의 주장이다.
- 실제 application data에는 시간적인 유사성이 존재한다.
기존의 TTA 방법은 위와 같은 시간적인 유사성이 있는 데이터에 대해서는 성능이 하락하는 문제가 있었다.
이러한 문제를 해결하기 위해, 논문의 저자들은 non-i.i.d. 상황에서도 robust한 test adaptation scheme을 만들었다.
- Instance-Aware Batch Normalization (IABN)
- out-of-distiribution sample에 대해서도 정확하게 normalization할 수 있다.
- Prediction-balanced Reservoir Sampling (PBRS)
- class-banaced 방식으로 non-i.i.d stream에서 i.i.d data stream으로 바꿔주는 역할을 한다.
Introduction
기존의 TTA연구들은 target test $t$시간의 sample $x_{t}이 independent하고 identically distributed 됐다고 가정했었다.
그러나 대부분의 application에서는, online test sample들은 종종 time에 따라서 distribution이 바뀐다.
- 예를 들어서, 차만 있는 고속도로에서는 detection이 잘 되더라도, 보행자 자전거가 있는 도심에서는 성능이 하락될 것이다.


저자들은 기존 TTA방법들은 batch에 들어온 시간적으로 연관이 있는 데이터의 temporal distribution에 overfitting되기 때문에 generalization 성능이 떨어진다고 이야기한다.
이러한 문제를 해결하기 위해, NOn-i.i.d TEst-time adaptation scheme (NOTE) 을 제안한다.
NOTE
- Instance-Aware Batch Normalization (IABN)
- sample by sample마다 out-of-distribution을 찾고, instance-aware normalization을 통해 보정해준다.
- 시간적 상관관계에 의존하지 않고, distribution shift에 잘 적응할 수 있게 된다.
- instance norm + batch norm
- 학습한 BN과 관찰한 IN의 차이만큼 보정하는 방법이다.
- sample by sample마다 out-of-distribution을 찾고, instance-aware normalization을 통해 보정해준다.
- Prediction-Balanced Reservoir Sampling (PBRS)
- non-i.i.d stream에서 i.i.d를 모방하여 샘플을 생성해서 non-i.i.d에 overfitting되는 문제를 해결했다.
- 모델의 predicted label을 활용해서, non-i.i.d stream에서 부터 time-uniform sampling 및 class-uniform sampling 하고 'simulated' i.i.d sample을 memory에 저장한다.
- 위에서 저장한 memory에 있는 i.i.d와 유사한 batch로, temporal distribution에 biased되지 않고 target domain에 adaptation할 수 있다.
- non-i.i.d stream에서 i.i.d를 모방하여 샘플을 생성해서 non-i.i.d에 overfitting되는 문제를 해결했다.
추가적인 장점도 있다.
- 기존 test batch의 통계에만 의존하던 TTA 방법과 다르게, batch-free inference로, 단일 instance로도 inference가 가능하다.
- Augmentation으로 performance를 향상시키는 방법들이 유행인데, 이는 추가적인 forward cost가 필요하지만, NOTE는 single forwarding pass면 충분하고, normalization statistics와 affine params만 학습하기 때문에 ResNet18기준으로 0.02%의 파라미터만 학습한다.
- 추가적으로 memory를 사용하기는 하지만, 무시할 수 있을 정도로 작다.
Method

Instance-Aware Batch Normalization
batchnorm은 batch에서 정보를 평균내면, $y$를 예측하는데에 필요없는 정보를 없앨 수 있다는 것이 시작이다.
그러나, batch에 temporal correlation이 있으면, 단순하게 정보를 평균내는 것으로는 temporal correlation을 제거할 수 없다.
그렇기 때문에, 기존 TTA의 batchnorm을 활용하는 방법으로는 temporal correlation이 있는 데이터에 대해서 성능이 낮은 것이다.

기존 batch만 보던 $(\bar{\mu}, \bar{\sigma}^{2})$를 instance-wise statics $(\tilde{\mu}, \tilde{\sigma}^{2})$ 를 고려한 Instance-Aware Batch Normalization $(\hat{\mu}_{c}, \hat{\sigma}_{c}^{2})$로 변환한다.


$\tilde{\mu}$와 $\hat{\mu}$가 크게 다를때만 IABN이 작동해야하니까

$\alpha$ 가 0보다 크게 설정하고, 이는 하이퍼 파라미터로 BN의 confidence level이다.
크면 BN 통계에 의존하고, 작으면 현재 instance의 통계에 의존한다.
실험에서는 4를 사용했다.
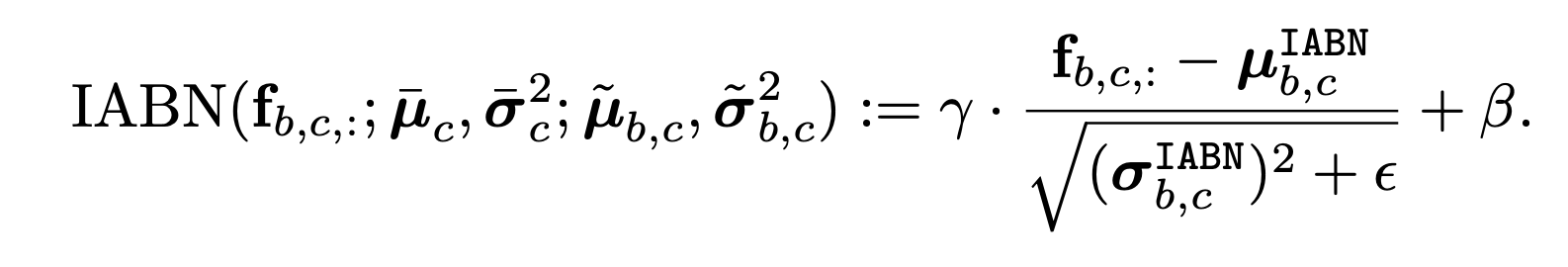
Adaptation via Prediction-Balanced Reservoir Sampling
약간의 메모리를 사용해서, temporally correlated stream에서 i.i.d sample인척 sampling하는 방법이다.
time-uniform sampling + prediction-uniform sampling으로 non-i.i.d. stream에서 simulate i.i.d sample을 만든다.
time-uniform sampling은 reservoir sampling을 사용해서 random sampling한다.
prediction-uniform sampling은 predicted label로 memory에 제일 많은 class를 찾고, 그 class의 instance를 랜덤으로 다른 걸로 바꿔준다.


'Papers > Domain Adaptation' 카테고리의 다른 글
| Continual Test-Time Domain Adaptation (0) | 2023.09.06 |
|---|---|
| TENT: FULLY TEST-TIME ADAPTATION BY ENTROPY MINIMIZATION (0) | 2023.09.06 |