
둔비의 공부공간
Toward domain generalized pruning by scoring out-of-distribution importance 본문
Toward domain generalized pruning by scoring out-of-distribution importance
Doonby 2023. 9. 26. 20:26https://arxiv.org/abs/2210.13810
Toward domain generalized pruning by scoring out-of-distribution importance
Filter pruning has been widely used for compressing convolutional neural networks to reduce computation costs during the deployment stage. Recent studies have shown that filter pruning techniques can achieve lossless compression of deep neural networks, re
arxiv.org
Accepted in Workshop on Distribution Shifts (NeurIPS 2022)
Abstract
Filter pruning의 다양한 장점들로 인해 연구가 많이 됐지만, 지금까지 cross-domain generalization에 대해서는 고려하지 않았다.
저자들은 intra-domain performance는 유지되지만, cross-domain performance는 유지되지 못하는 것을 다양한 실험을 통해 보였다.
이를 해결하기 위해 저자들은 filter importance를 재정의했다.
- unseen distribution의 pruning risk를 줄이기 위해, domain-level risk의 variance를 이용하여 importance를 정의했다.
- 이러한 importance로 pruning을 하여 domain generalized된 filters를 많이 남길 수 있었다.
그 결과로, 동일한 pruning ratio로 cross-domain generalization performance가 상당히 좋아지는 것을 보였다.
저자들은 이번 연구가 domain generalization + filter pruning research의 첫 연구라고 한다.
Introduction
Pruning의 목표는 최대의 compression으로, 최소의 정확도 손실을 목표로 한다.
하지만, 기존 pruning은 cross-domain에서의 상황을 전혀 고려하지 않아, train과 test data의 distribution이 다른 real-world에서의 성능은 크게 떨어질 수 있다고 주장한다.
기존의 pruning-finetuning paradigm에서는 filter's importance score를 계산하고, 중요도가 작은 filter를 masked하거나 pruned하기 때문에 scoring은 pruning에서 제일 중요한 부분이다.
scoring은 대부분 magnitude, gradient based, feature information등을 사용하고 "independent and identically distributed assumption"에서 동작하는 것을 가정했지만, "Out-of-Distribution" 환경은 전혀 고려하지 않았다.
그러므로, 아무리 중요도가 낮은 neurons을 pruning하여도 unseen target data domain에 대해서는 예상치못한 성능 하락이 생길 수 있다.
이를 해결하기 위해 이 논문에서는 "Importance of out-of-distribution Risk (IoR)"를 제안했다.
- domain level risk variance의 gradient information을 포함하여 importance를 계산하는 방법이다.
Preliminary
$M$ filters의 파라미터를 $\{\theta_{1}, \theta_{2}, ..., \theta_{M} \}$ 라고 하자.
$N$개의 data domain 이 $\{ D_{1}, D_{2}, ..., D_{N} \}$이 있을때, importance는 아래와 같다.

각 data domain에 대해서, dense 모델과 empirical risk와 sparse 모델의 empirical risk의 차이이다.
first-order taylor expansion에 의해서 위의 식은 아래로 근사할 수 있다.
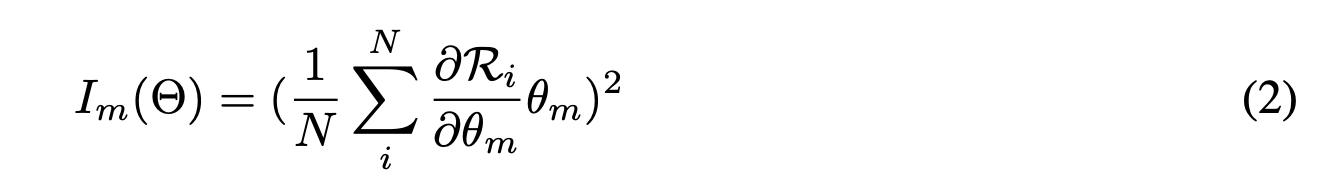
위의 식은 간단하게 말하면, $\theta_{m}$을 pruning했을때의 얼마만큼 risk가 증가할 것인가?를 측정하는 것이다.
이 방법은 i.i.d 환경에서는 문제가 되지 않지만, train과 test의 distribution이 다를 경우 중요도가 달라질 수 있게 된다.
Unseen domain에서의 test 성능하락을 줄이기 위해, 중요도 계산하는 방법을 바꿔서 더 일반화가 잘 되는 filter를 선택하고, 그렇지 않은 filter는 pruning하는 방법을 제안했다.
Scoring out-of-distribution importance
위에서 설명한대로 out-of-distribution risk을 고려해서 importance score를 재정의해봤다.
이때, risk extrapolation 에서 영감을 받아서, out-of-distribution risk $R^{0}$은 아래 식으로 근사했다.

위를 고려하여 2번 식을 개선했다.

Experiments
Research Question
- Will filter pruning affect the domain generalization performance?
- ERM으로 ResNet18, ResNet50을 pretrain한 모델을 사용했다.
- baseline pruning method로 pruning rate 50%, 70%를 pruning했다.
- ResNet18-30%, ResNet50-30% (70% pruning rate)
- ResNet18-50%, ResNet50-50% (50% pruning rate)
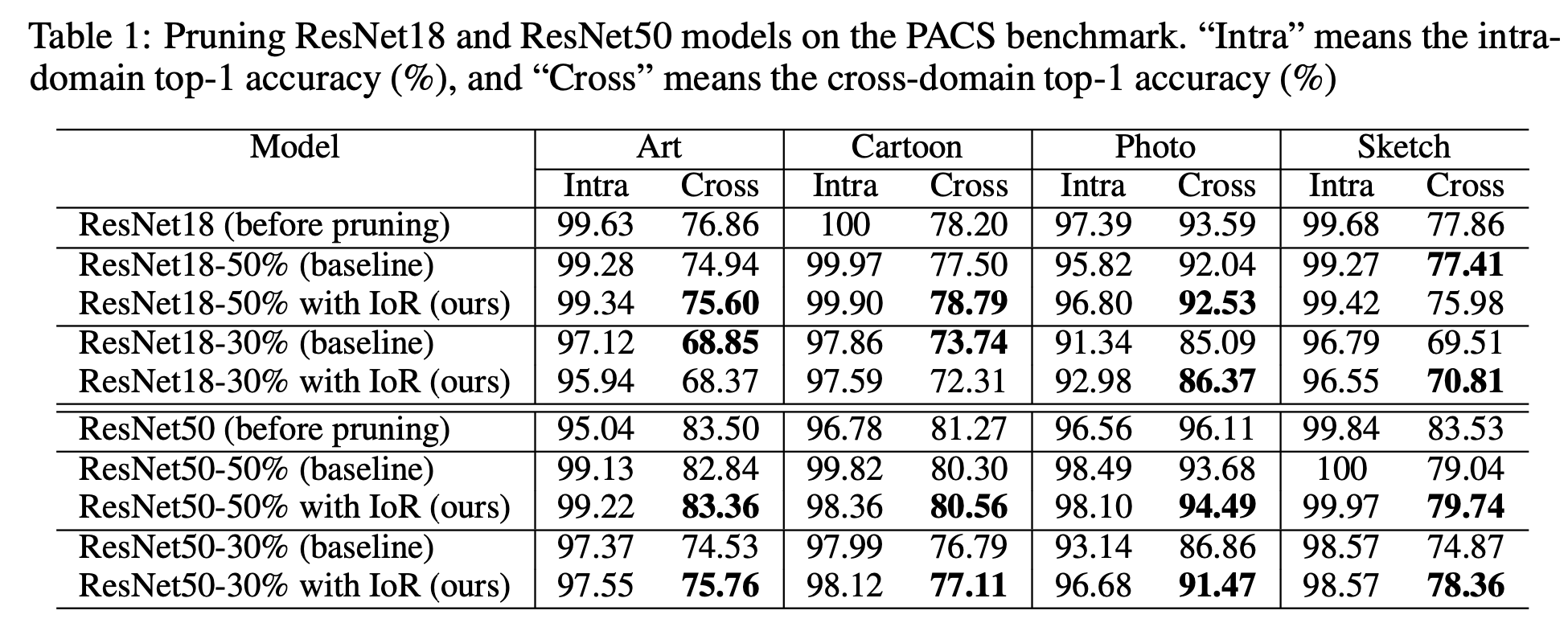
- Can we reduce the sacrifice of the cross-domain performance from pruning?
- 위의 Table 1을 보면, 논문에서 제안한 IoR을 사용한 것이 Cross domain의 성능하락을 줄여준 것을 볼 수 있다.
- 추후에 더 좋은 criteria를 제안하여, cross-domain generalization performance의 성능하락을 더 줄여볼 계획이라고 한다.
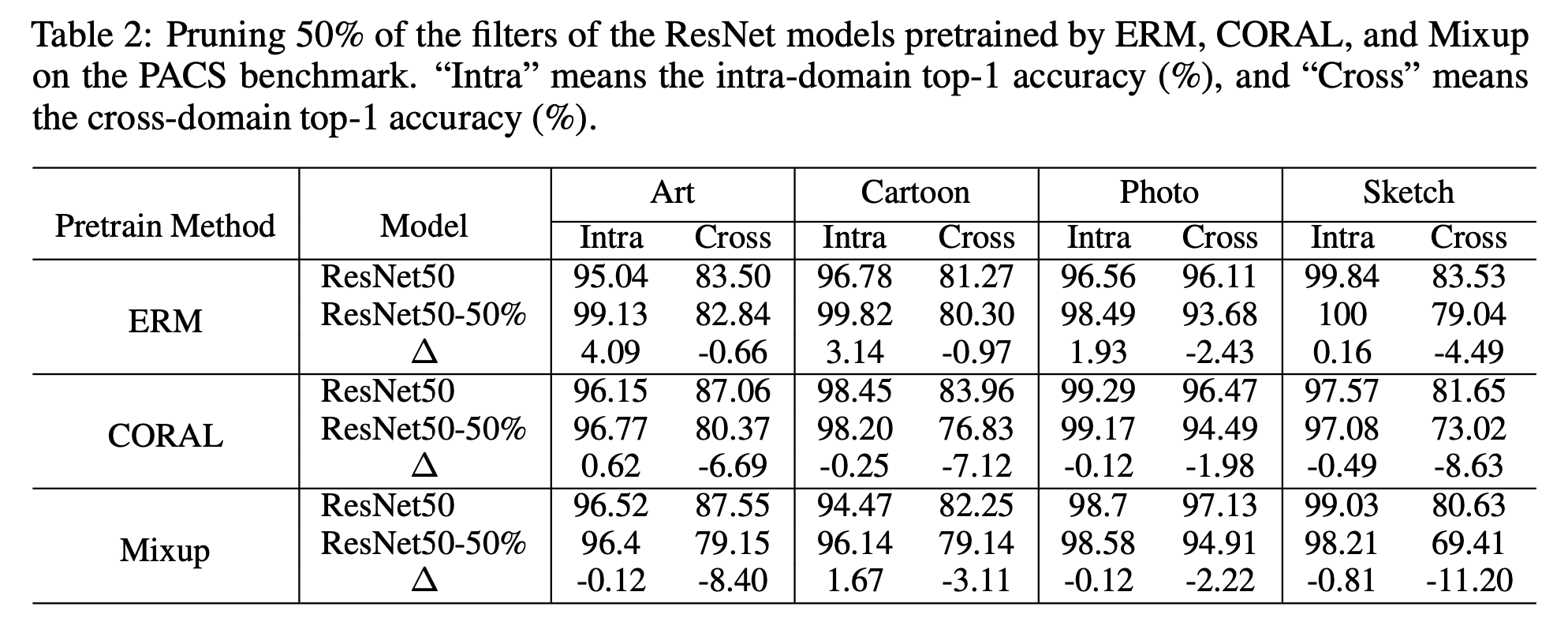
- Is a model pretrained by domain-generalization methods more than ERM robust after pruning?
Conclusion
pruning에서 추구하는 "lossless", 즉 무손실 압축은 intra-domain에서는 가능하지만, cross-domain에 적용할 수 없었다.
또한 기존 domain generalization 방법들을 사용하더라도, pruning의 acc의 성능하락을 막을 수 없었다.
하지만, 논문에서 제안한 IoR을 이용하여 cross-domain에서 pruning acc의 성능하락폭을 감소시킬 수 있었다.
저자들은 이번 연구가 pruning과 domain-generalization을 묶는 첫 시도이며, 더 많은 관심을 갖게 되기를 바란다고 마무리했다.
(개인생각)
최근에 생각해본 주제긴 한데, 푸는 방향이 내가 구상한 방법과는 조금 다르다.
오히려 생각한 방법보다 쉽게 접근한 것 같다.
조금 더 고민해 볼 수 있는 분야인 것 같다.
'Papers > Compression' 카테고리의 다른 글
| Multi-level Logit Distillation (1) | 2023.12.08 |
|---|---|
| DOT: A Distillation-Oriented Trainer (1) | 2023.11.23 |
| Prune Your Model Before Distill It (0) | 2023.08.17 |
| Triplet Knowledge Distillation (0) | 2023.07.26 |
| Hyperpruning: Efficient Hypersearch over Network Pruning Through Lyapunov Metric (0) | 2023.06.29 |



