
둔비의 공부공간
SINGLE TEACHER, MULTIPLE PERSPECTIVES: TEACHERKNOWLEDGE AUGMENTATION FOR ENHANCED KNOWLEDGE DISTILLATION 본문
SINGLE TEACHER, MULTIPLE PERSPECTIVES: TEACHERKNOWLEDGE AUGMENTATION FOR ENHANCED KNOWLEDGE DISTILLATION
Doonby 2025. 3. 16. 23:41ICLR 2025 Accpeted
https://openreview.net/forum?id=DmEHmZ89iB
Single Teacher, Multiple Perspectives: Teacher Knowledge...
Do diverse perspectives help students learn better? Multi-teacher knowledge distillation, which is a more effective technique than traditional single-teacher methods, supervises the student from...
openreview.net
기존 KD와 다르게, Multi-teacher를 사용해서 더욱 다양한 관점을 student에게 전달하는 논문들이 많이 나왔었다.
하지만, 이런 방법들은 서로 다른 teacher들을 학습시켜야하는 불편함이 있었다.
이 논문에서는 단 하나의 teacher만 사용해서 추가적인 학습없이, 다양한 관점을 distillation할 수 있는 방법을 제안한다.

방법은 간단하다.
"Gaussian Noise"를 feature distillation이면 representation에, logit distillation이면 output logits에 넣는 것이다.
이러면, 동일한 input에 대한 다양한 gaussian noise가 추가된 정보들을 함께 받으면서 다음과 같은 효과를 누릴 수 있다.
- feature의 경우, 더 넓은 스펙트럼의 feature representation을 전달할 수 있다.
- 마치 drop-out이나, data augmentation 처럼 말이다.
- logits의 경우, 더욱 다양한 inter-class relationship을 올려줄 수 있다.
- One-hot vector를 전달하는 cross-entropy와 다르게, KD는 soft logits (ex) [0.1, 0.2, 0.1, 0.6]) 을 전달하면서 student에게 "regularize"를 하는 효과를 낼 수 있는데, 이를 Gaussian noise로 추가함으로써, 좀 더 다양한 inter-class relationship을 전달하는 것이다.
<Feature distillation + Synthesis feature distillation>
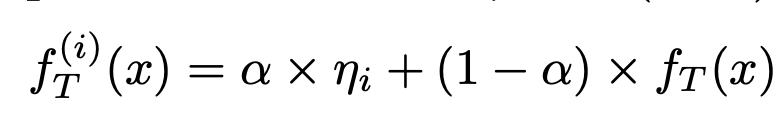
$i$마다 새로운 Gaussian noise가 있고, 해당 noise와 teacher의 feature를 interpolation해준다.
이때, $\alpha$ 값은 0.1을 사용했다.

interpolation한 $f^{(i)}_{T}(x)$ 와 student의 feature $f_{S}(x)$와 $i$만큼 distillation을 해주고
합성하지 않은 원본 feature도 첫번째 항에서 distillation 해준다.
<Logits distillation + Synthesis logits distillation>

마찬가지로, $i$마다 새로운 Gaussian noise가 있고, 이 noise와 teacher의 logits $z_{T}(x)$를 interpolation해준다.
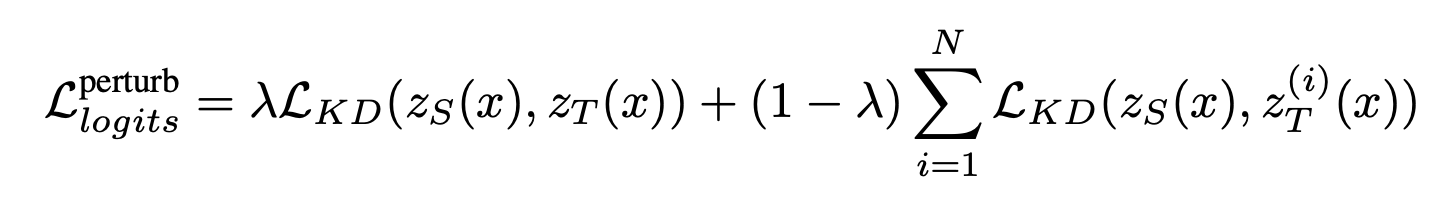
interpolation한 $z_{T}^{(i)}(x)$와 student의 $Z_{S}(x)$를 일반적으로 사용하는 KL Divergence loss로 distillation해준다.
합성하지 않은 원본 logits도 첫번째 항에서 distillation 해준다.

CIFAR10에서의 기존 KD(logits), CRD(Feature)와 비교한 table이다. (L)은 $L_{logits}^{perturb}$ loss를, (F)는 $L_{feat}$ loss를 말한다.

single teacher방법과 multi-teacher 방법에 TeKAP loss term을 추가했을때 성능이 향상되는 것을 보였다.

ImageNet에서 Teacher ResNet34 -> Student ResNet18로 distillation 했을때, 기존 KD보다 error rate가 줄어듬을 보였다.

Vanilla student나 기존 KD보다 inter-class의 correlations가 줄어드는 것을 보였다.
내가 실험했을때와 크게 다른점은 ImageNet 실험인 것 같다.
기본적으로 DKD나 다른 논문들의 ImageNet의 table을 사용하지 않고, 단순 KD와 비교하는 table을 많이 사용한 것 같다.
또한, Adversarial robustness나 few-shot, imbalance class dataset 등 다양한 세팅에서 table을 채웠다.
내가 리뷰어였으면 최신 SOTA의 ImageNet을 물어봤을 것 같긴 하다.
이번에 이 논문이 ICLR2025에 붙으면서, 이 논문의 테이블들을 그대로 가져다가 만들어도 될 것 같다.
'Papers > Compression' 카테고리의 다른 글
| Dataset Quantization (1) | 2024.10.31 |
|---|---|
| Variation-aware Vision Transformer Quantization (0) | 2024.09.13 |
| Learned step size quantization (1) | 2024.09.10 |
| DaFKD: Domain-aware Federated Knowledge Distillation (0) | 2024.07.31 |
| Complement Sparsification: Low-Overhead Model Pruning for Federated Learning (0) | 2024.07.09 |



