https://arxiv.org/abs/1506.02626 (Standford, Nvidia NIPS 2015)
Learning both Weights and Connections for Efficient Neural Networks
Neural networks are both computationally intensive and memory intensive, making them difficult to deploy on embedded systems. Also, conventional networks fix the architecture before training starts; as a result, training cannot improve the architecture. To
arxiv.org
Abstract
Neural Network는 computation, memory cost가 높기 때문에 embedded system에 올리기는 힘들다.
위와 같은 한계를 해결하기 위해, 성능은 유지하되 storage와 computation 요구사항을 줄일 수 있는 방법을 소개한다.
이 논문에서는 3개의 step을 통해서 pruning을 진행한다.
- train the network to learn which connections are important
- prune the unimportant connections
- retrain the network to finetune the weights of the remaining connections
ImageNet에 대해 정확도의 손실 없이, AlexNet은 9배 압축, Vgg16는 13배 압축에 성공했다.
Introduction
Neural Network가 강력하지만, 높은 cost 때문에 embedded system에 사용하기 어렵다.
SRAM과 DRAM에 따라서 bit별 요구되는 energy가 다른데, DRAM은 640pJ for 32bit다.
예를 들어, 20Hz에서 1billion network를 돌리기 위해서는 DRAM access에만 $(20Hz)\,*\,(1G)\,(640pJ)\,=\,12.8W$가 필요하다.
이는 mobile등에 올리기엔 턱없이 부족하다. 이를 mobile에서도 real time으로 구동할 수 있도록 하는 것이 목표이다.
이를 달성하기 위해, 정확도는 그대로 유지한채로 network의 connection을 prune 하는 방법을 소개한다.
첫 번째로, initial training phase가 끝난 후, weight가 threshold보다 작은 connection을 모두 제거한다.
이 pruning은 dense 한 fc layer를 sparse layer로 만들 수 있다. 이 과정에서 network의 topology를 학습한다.
- connection별 중요도에 대해서 학습한다.
둘째로, 남은 connection에 대해서 재학습한다.
위의 과정을 압축률에 따라서 iteratively 반복할 수 있다.
Learning Connections in Addition to Weights
논문의 pruning은 3개의 step으로 구성되어 있다.
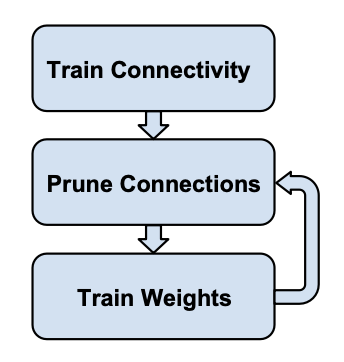
- 일반적으로 training을 하지만, prediction에 중점을 두지 않고, 어떤 connection이 중요한지를 학습한다.
- threshold보다 낮은 모든 connnection을 제거한다.
- 남은 weight로 재학습을 진행한다.
- 이 과정이 없으면 성능에 상당한 영향을 미친다.

Regularization
L1은 최대한 0에 가깝게 규제를 한다. pruning직후에 정확도가 높은 특징이 있는데, retraining까지 하고 난 이후에는 L2가 더 정확도가 높다. pruning 할 때 L1을 쓰고 retraining 할 때 L2를 써도, L2 만 쓴 것보다 못했다.
다른 규제를 사용한 파라미터에 대해서 다른 규제를 적용하는 것이 잘 작동되지 않는다.

Dropout Ratio Adjustment
Dropout은 overfitting방지용으로 많이 사용하는데, retraining에도 적용할 수 있다. (압축률을 고려해서 정해야 함)
이 dropout 비율은 다음과 같이 정한다.
$C_{i} = N_{i} N_{i-1}$, $D_{r} = D_{o} \sqrt {\frac {C_{io}}{C_{ir}}}$
$C_{i}$는 i layer의 connection 개수
$N_{i}$는 i layer의 neuron 개수
$C_{io}$는 original model의 i layer의 connection 개수
$C_{ir}$는 retrained model의 i layer의 connection 개수
$D_{o}$는 original model의 dropout rate
$D_{r}$는 retrained model의 dropout rate
Local Pruning and Parameter Co-adaptation
Pruning이 끝난 후에 남은 weight를 초기화하지 않고, 그대로 학습을 하는 것이 더 좋다.
또한 weight가 pruning과정에서 줄었으므로, backpropagation에 필요한 computation도 줄게 된다.
다만, gradient vanishing문제에 취약해서, conv layer를 freeze 하고 fc만 pruning 하고, conv를 pruning 할 땐 반대로 한다.
Iterative Pruning
iterative 과정에서 좋은 connection을 학습하게 된다.
(pruning + retraining)을 한 번의 과정이라고 할 때, 이를 여러 번 반복해서 최소한의 connection을 찾을 수 있다.
- greedy search방식
iterative 한 방법이 한 번에 pruning 하는 것보다 정확도 손실 없이 AlexNet에 대해서 5~9배의 압축을 할 수 있다.
Pruning Neurons
connection을 pruning 한 후에, neurons을 보면 input or output connection이 없는 neuron들을 제거할 수 있다.
해당 neuron은 output에 기여한 게 없으므로, backpropgation이 흐르지 않고, regularization은 이런 뉴런들을 0에 가깝도록 조정한다.
그러므로 connection만 제거하고 training 하는 과정에서 자동적으로 제거된다.
Experiments

Code
(github)
def structured_prune(self, model, prune_rate):
# get all the prunable convolutions
convs = model.get_prunable_layers(pruning_type=self.pruning_type)
# figure out the threshold of l1-norm under which channels should be turned off
channel_norms = []
for conv in convs:
channel_norms.append(
torch.sum(
torch.abs(conv.conv.weight.view(conv.conv.out_channels, -1)), axis=1
)
)
threshold = np.percentile(channel_norms, prune_rate)
# prune anything beneath the l1-threshold
for conv in convs:
channel_norms = torch.sum(
torch.abs(conv.conv.weight.view(conv.conv.out_channels, -1)), axis=1
)
mask = conv.mask * (channel_norms < threshold)
conv.mask = torch.einsum("cijk,c->cijk", conv.weight.data, mask)
def unstructured_prune(self, model, prune_rate=50.0):
# get all the prunable convolutions
convs = model.get_prunable_layers(pruning_type=self.pruning_type)
# collate all weights into a single vector so l1-threshold can be calculated
all_weights = torch.Tensor()
if torch.cuda.is_available():
all_weights = all_weights.cuda()
for conv in convs:
all_weights = torch.cat((all_weights.view(-1), conv.conv.weight.view(-1)))
abs_weights = torch.abs(all_weights.detach())
threshold = np.percentile(abs_weights, prune_rate)
# prune anything beneath l1-threshold
for conv in model.get_prunable_layers(pruning_type=self.pruning_type):
conv.mask.update(
torch.mul(
torch.gt(torch.abs(conv.conv.weight), threshold).float(),
conv.mask.mask.weight,
)
)