
둔비의 공부공간
The Generalization-Stability Tradeoff In Neural Network Pruning 본문
The Generalization-Stability Tradeoff In Neural Network Pruning
Doonby 2023. 6. 13. 16:19https://arxiv.org/abs/1906.03728
The Generalization-Stability Tradeoff In Neural Network Pruning
Pruning neural network parameters is often viewed as a means to compress models, but pruning has also been motivated by the desire to prevent overfitting. This motivation is particularly relevant given the perhaps surprising observation that a wide variety
arxiv.org
(2020 neurips)
일반화 분야에서 flatness는 주로 loss landscape를 말하며, 이게 평탄할수록 필요한 변수의 개수가 적음을 의미하고, 이는 일반화성능이 좋아질 수 있음을 의미한다고 한다.
What can flatness teach us: understanding generalisation in Deep Neural Networks
This is the third post in a series summarising work that seeks to provide a theory of generalisation in Deep Neural Networks (DNNs)…
towardsdatascience.com
논문의 간단 요약!
pruning은 파라미터 감소와 무관하게 noise injection의 관점에서 regularize와 비슷하다!
pruning후 성능이 떨어질수록 추후에 일반화 성능이 크게 오르더라!
물론, 그 성능이 떨어지는 (불안정성)이 너무 크면 안되긴 하더라!
Abstract
사람들이 프루닝 network는 모델 압축이라고 생각하는데, 실제로는 overfitting을 방지하는 것에서 시작됐다고 한다.
대표적으로 pruning 방법을 적용했을 때, 파라미터 수를 줄였음에도 test정확도가 오르는 실험이 있었다.
network의 파라미터수를 줄임으로 써, overfitting이 해결되고 일반화성능이 향상되는 것을 말하는 듯...?위의 해석은 논문의 의도랑은 다른 것 같은데, pruning을 했더니 최종모델의 테스트 성능이 오른 것을 경험적으로 확인한 사례들을 말하는게 아닐까....?
위와 같은 현상을 이해하기 위해, 훈련 과정에서 pruning 동작을 분석했는데, pruning의 불안정성으로 인해 일반화 성능이 오르는 것을 확인했다.
Pruning 불안정성이란, pruning을 진행한 직후의 test accuracy가 하락하는 현상을 말한다.
논문에서는 이런 "generalization-stability tradeoff"관계가 다양한 프루닝 방법에 모두 존재하며, noise injection과 유사한 pruning regularize가 원인이라는 것을 증명했다. 위의 증명을 뒷받침하는 결과는, pruning 불안정성이 커지면, 모델이 flatness해지는 경향이 있고, pruning의 이점이 parameter removal에 의존하지 않는다는 것이다.
generalization 분야에서, model의 flatness는 주로 loss landscape의 평탄도를 말하고, 이게 평탄할수록 설명하는데 필요한 변수가 적기 때문에, 일반화가 잘 된다는 이야기가 있다.pruning과정에서 파라미터 수가 줄어서, loss landscape가 평탄해지는건 결국 parameter removal 때문이 아닌가? 하는 의문이 생기긴 한다.
이러한 결과는 pruning-based generalization improvement의 연관성과 최근 overparameterized network에서 관찰되는 높은 일반화 성능을 설명할 수 있다.
Introduction
최근 DNN의 일반화 연구는 "parameters를 추가하면, 일반화 성능을 향상시킬 수 있다"는 부분에 집중하고 있다. 큰 dataset의 random shuffle data로 충분한 parameters를 갖고 있는 네트워크를 학습시킨 경우에도 마찬가지다.
이러한 연구들은 paramter 개수 외의 generalization 척도를 연구했다. 연구들에선 일반화 성능이 높지만, overparameterized된 DNN을 광범위하게 적용하기 위해서는 memory footprint와 inference FLOPs를 줄이는 것이 필요하며, 정확도를 해치지 않으면서 파라미터 수를 크게 줄일 수 있는 pruning을 통해 이를 달성할 수 있고, pruning자체가 일반화 성능을 올리는데 도움이 되기도 한다고 말했다.
memory footpring 이란, 메모리 사용량 같은 것을 의미한다.
위의 의견대로라면, 아래같은 의문이 생길 수 있다.
- 파라미터 개수가 많다고해서 Overparameterized DNN의 overfitting이 증가하지 않는다면, pruning으로 학습중에 DNN의 파라미터를 줄이는 것이 일반화성능을 높일 수 있는 이유는 무엇일까?
- Overparameterized DNN에서 큰 파라미터수가 overfitting을 시키지 않는다면, 왜 학습중에 pruning하는 것이 일반화에 도움이 되는걸까?
논문에서는 이러한 것의 대답을 parameter수와 별개로, pruning의 regularization mechanism관점에서 설명한다.
특히, 논문에서는 간단한 magnitude pruning이 noise-injection regularization과 비슷한 효과가 있음을 보였다.

대부분의 pruning은 pruning으로 파라미터를 줄여도, 기존에 학습한 성능을 보존하려고 하기 때문에, 안정성이 목표인 경우가 많다.
그렇기에, 작은 weight를 지워서 네트워크에 영향이 적게 가도록 하는 것이 보편적이다.
하지만, 논문의 실험에서는 큰 weight를 지웠을때 작은 weight를 지웠을때보다 일반화 성능이 증가하는 것을 확인했다.
이러한 결과는 pruning이 DNN 일반화 성능에 미치는 영향이 최종 파라미터 수보다 안정성에 더 큰 영향을 미친다는 가설에 확신을 주었다.
그러므로, 학습 중에 noise representation을 통해 pruning이 정규화될때 까지는 stable pruning이 좋은 방법이 아닐 수 있다.
실험 결과상 pruning으로 noise가 생기고, "성능이 떨어져야" 일반화가 오르기 때문에, "안정성"을 목표로 학습하면 일반화를 올리지 못한다는 의미인 것 같다.
generalization-stability tradeoff에서 파라미터 감소 없이도(largest/smallest magnitude 똑같이 하나를 지워도, 안정성의 반비례), 일반화성능이 오를 수 있다는 것을 확인했지만, 우리가 알고있는 deep learning 상식으로는, 일반화성능을 올리는 것에는 파라미터 감소가 필요하다고 알고 있다.
위 두개는 모순인데, 논문에서 세운 가설을 검증하기 위해 pruning한 후에, pruned connection을 살려봤는데, pruned connection이 살아나면서 파라미터의 개수는 똑같지만, 일반화 성능이 높아진 것을 확인할 수 있었다.
논문에서는 위와 같이 pruning stability를 낮추면, DNN의 flatness가 높아져서 일반화 성능이 오른다는 가설을 세웠다. 실험 결과, pruning stability는 더 나은 일반화 성능과 관련된 여러 flatness측정치와 반비례하는 것을 보였다.
따라서, pruning과 Overparameterized는 같은 이유로 DNN 일반화를 개선할 수 있으며, flatness는 Overparameteried DNN에서 이상하게 높은 일반화 수준의 원인으로 의심되는 요소이기도 하다.
Approach
일단 이 논문의 목표는, pruning <-> generalization performance의 관계에 대해서 이해하는 것이다.
다양한 magnitude pruning algorithm으로 여러 generalization improvement와 stability levels를 생성해서 연구를 진행했다.
generalization level은 "generalization gap"을 반영했다.
각 실험에서, 모든 하이퍼파라미터들은 10번씩 실행했고, 10번을 다 plot하거나 mean을 해서 plot을 했다.
Models
- VGG11 with batchNorm and dense layers -> single dense layer
- ResNet18, ResNet20, ResNet56
Optimization
- Adam
- pruning 후에 회복할때는 SGD보다 Adam이 좋았다.
- pruning에서 회복할때, learning rate가 낮으면 회복이 어려웠다는 관측과 관련이 있을 것이다. (To prune, or not to prune: exploring the efficacy of pruning for model compression)
Data
- cifar10
- random crop, horizontal fips, batchsize 128
Regularization
- $L1$이나 $L2$ regularization을 거는 순간, pruning의 일반화 성능 실험 결과 비교가 어려우니, 제외했다.
Computing flatness
- Hessian of the loss $H$는 parameter가 변경됐을때 gradient의 민감도를 말한다.
- gradient covariance matrix $C$는 sampled input이 변경됐을때 gradient의 민감도를 말한다.
Experiments
The generalization-stability tradeoff
이번 챕터에서 해결하고 싶은 질문은 아래와 같다.
pruned DNN의 일반화 성능향상은 파라미터 개수 감소가 중요할까? pruning 알고리즘이 중요할까?
pruning으로 파라미터를 줄이는 게 training data에 overfitting되는 것을 방지 한다면, pruned DNN의 지워진 파라미터가 많을 수록 일반화 성능이 향상될 것이라고 예상할 수 있다. 혹은 pruning 알고리즘에 따라 일반화 성능이 결정될 수 있다.
이 실험에서는 layer별로 동일한 양의 파라미터를 지우고, pruning 알고리즘에 따라서 일반화 성능의 변화를 비교해봤다.
논문의 저자들은 각 pruning algorithm에 대해서 다양한 pruning targets와 iterative pruning rates로 stability와 final test accuracy를 비교했다.
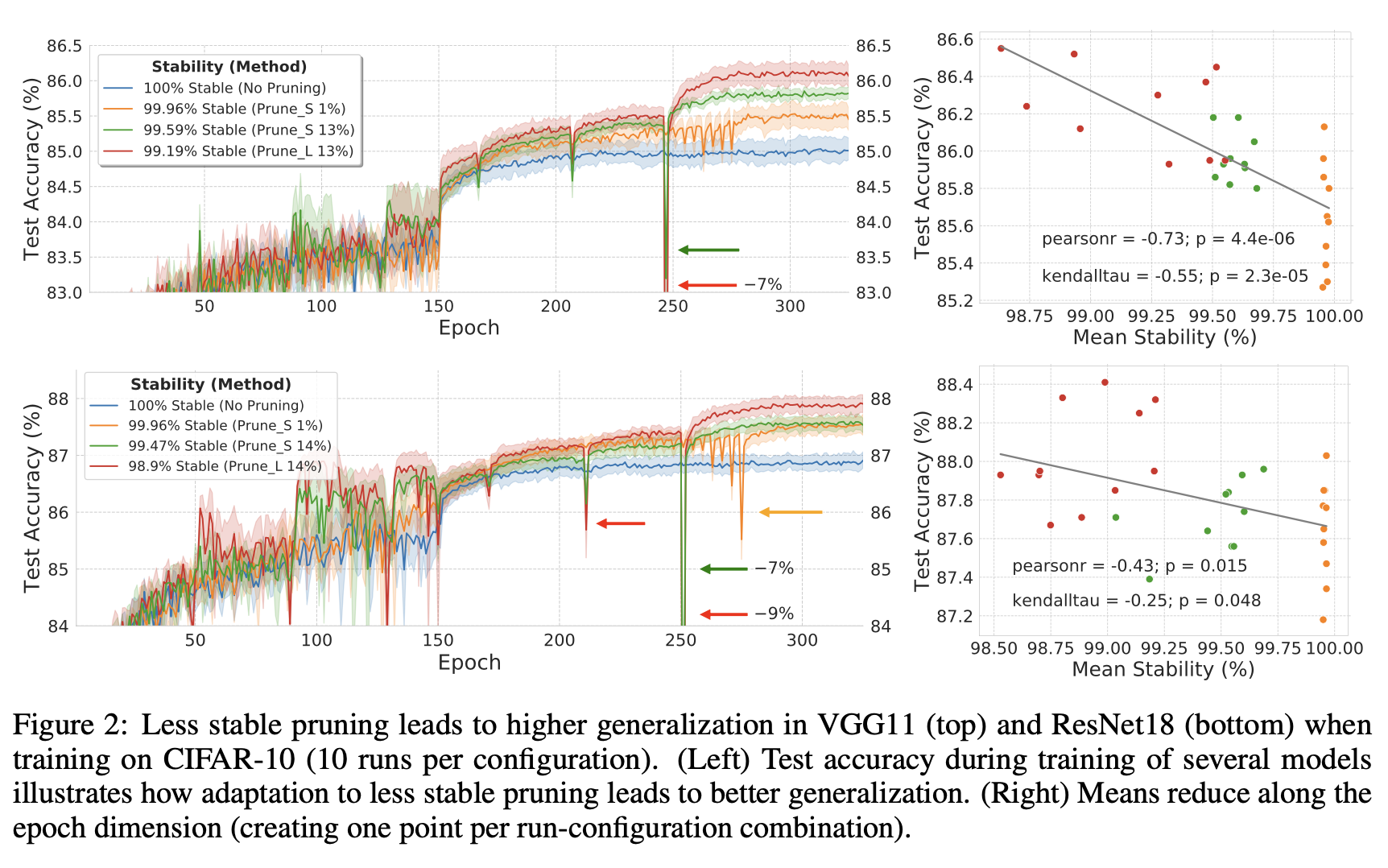
안정성이 낮은 pruning 알고리즘이, 안정적인 알고리즘보다 최종 test acc가 더 높았다. (그림 2의 오른쪽 VGG11, ResNet18)
피어슨 상관계수 $r$과 유의확률 p-value $p$를 지표로 사용하고 있다.
피어슨 상관계수란, 두 변수 $X$와 $Y$간의 선형 상관 관계를 계량화한 수치로, $-1 <= r <= 1$의 범위를 갖는다. normalized된 애들의 유사도를 측정할때 많이 사용한다.
p-value란, 특정 귀무 가설 맞다고 가정할때 얻은 결과보다 극단적인 결과가 실제로 관측될 확률이다.$0<= p <= 1$의 범위를 갖는다.
대부분의 pruning 알고리즘들이 최대한 안정적이도록 하는 것에 중점을 두는 반면에, 위와 같은 결과들은 불안정할때 더 일반화가 잘 되도록 한다는 것을 의미한다. 즉, 안정성과 일반화성능은 tradeoff 관계를 갖는다는 것이다.
파라미터의 개수나 architecutre-based arguments로는 위 실험의 pruned DNN의 일반화 성능을 설명할 수 없다.
그림2의 Prune$_{L}$를 보면, 다른 pruning 방법들 보다 지속적으로 불안정해지는 것을 확인할 수 있다. 하지만, pruning이 성능을 떨어트렸음에도 불구하고, network는 작은 epoch만으로도 빠르게 성능을 회복했다. 각각의 이러한 pruning 방법들은 빨간 색 화살표로 강조되어있다.
- Prune$_{L}$은 high iterative pruning rate를 갖고 진행한 pruning이다. 각 iteration마다 conv의 최대 14%까지 프루닝한다.
Towards understanding the bounds of the generalization-stability tradeoff
이 챕터에서는 아래 궁금증에 대해서 해결해본다.
그림 2에서, 안정성이 떨어지는 pruning 알고리즘이, 더 높은 일반화 성능을 만드는 것을 봤다. 항상 안정성이 떨어지는게 일반화 성능을 높이는 것이 맞는걸까?
작은 DNN를 SGD로 훈련하면 이점이 있나?
Impact of iterative pruning rate on the generalization-stability tradeoff
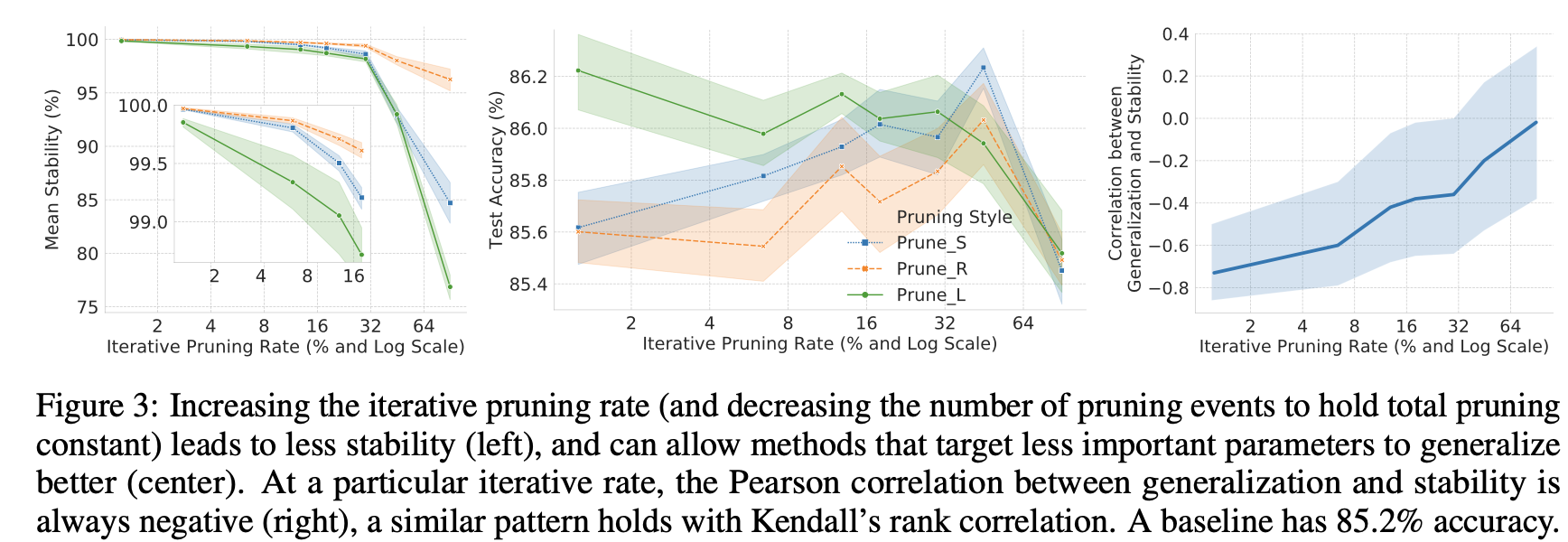
VGG11의 특정 pruning target, total pruning 비율에 대해서 iterative pruning rate를 maximal one-shot-pruning수준까지 올리면, pruning 안정성은 감소하는 것을 볼 수 있다. (그림3의 왼쪽)
따라서, 만약 항상 불안정한게 좋은거라면, iterative pruning rate를 올릴수록 일반화 성능이 좋아지는걸까? 하고 예상할 수 있다.
이를 테스트하기 위해 세 가지 pruning target에 대해 iterative pruning rate와 test accuracy를 비교했다. (그림 3의 가운데)
초기에 안정성이 높은 pruning target (Prune$_{S}$ 및 Prune$_{R}$)의 경우 iterative pruning rate를 높여 안정성을 낮추면 one-shot pruning 정도까지 일반화가 더 잘 이뤄진다.
하지만, pruning target이 initial iterative rate (PruneL)에서 안정성이 낮을때, 안정성을 더 낮추면 일반화성능이 낮아질 수 있다. 이러한 결과는 generalization-stability trade off가 광범위한 iterative pruning rate에 존재하지만, 결정적으로 안정성이 이미 낮은 수준에 도달하면 더 이상 일반화 성능이 오르지 않는 한계가 있음을 알 수 있다.
iterative pruning rate가 증가함에 따라 generalization-stability tradeoff의 연관성이 약해지는 것을 확인했다. (그림3의 오른쪽)
그래도 iterative rate가 커지면 상관관계가 의미가 없어지긴 했지만, 항상 거의 대부분의 구간에서 tradeoff 관계가 있기는 했다.
이러한 결과는 안정성이 threshold를 넘어서면 일반화 성능이 감소할 뿐만 아니라, 안정성이 감소함에 따라 tradeoff 연관성 자체도 감소한다는 것을 의미한다. 그러므로 안정성 감소가 가장 도움이 되는 '스위트 스팟'이 있음을 의미한다.
Impact of traditional training and pruning on the generalization-stability tradeoff
위의 그림2 실험은, augmentation이나 decay 같은 것을 제외하고, Adam으로 실험을 진행했다.
generalization과 stability의 관계를 측정하면서 중요도를 조사했다. (SGD + weight decay + augmentation)
게다가, 각 블록의 conv filter에 대해서 10%정도씩만 pruning하는 것으로 단순화하고, $l_{1}$ norm으로 filter의 점수를 메겼다.
파라미터는 training의 epoch {41, 71, 101}마다 세번에 걸쳐서 제거하거나, 두번 {41, 101}에 걸쳐서 제거하면서, 약 3% and 5%의 iterative rates를 만들었다.
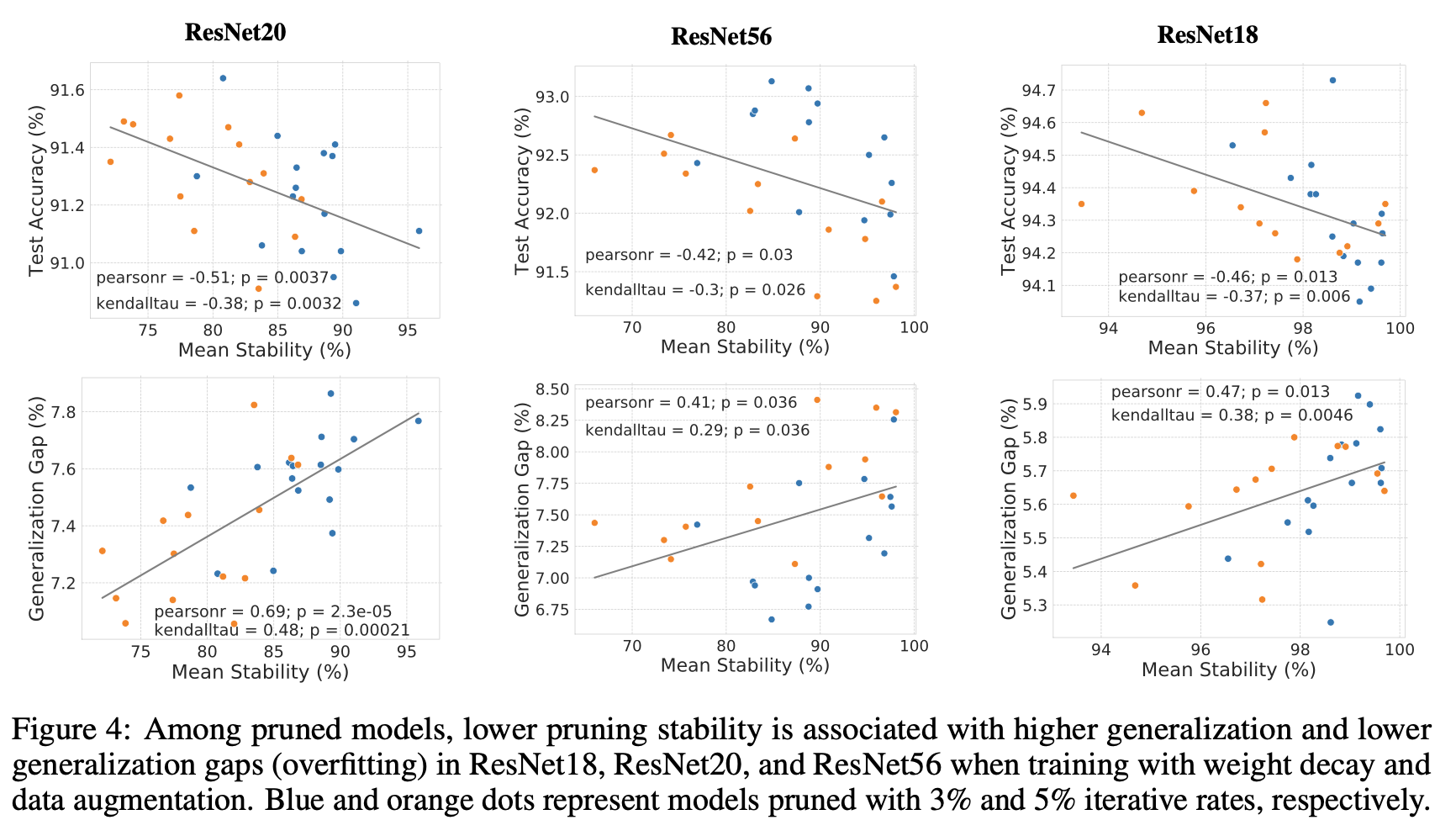
Impact of total pruning percentage on the generalization-stability tradeoff
그림2에서 ResNet18의 total pruning percentage를 46%에서 59%로 올렸고, generalization-stability tradeoff가 여전히 존재하는 것을 확인했다. 그러나 Prune$_{L}$은 너무 불안정성이 높아졌고, 큰 weight의 pruning이 좋지 않다던 기존 연구들과 마찬가지로, 높은 total pruning rate에서 Prune$_{S}$를 이기지 못했다.
이러한 결과를 종합하면, generalization-stability tradeoff는 광범위한 pruning hyperparameters에 존재했지만, pruning stability가 threshold 이하로 떨어지면, 더 안정성을 낮춰도 일반화 성능이 오르지 않았음을 알 수 있다. 이러한 결과로 낮은 안정성은 무조건 좋은게 아니라, tradeoff의 일부로 생각해야한다. 마치 드롭아웃을 80%이상으로 걸면 일반화 성능이 낮아지는 것과도 비슷하다.
Iterative magnitude pruning as noise injection
가중치를 다시 살려서, pruning의 영구성을 제거하면 pruning의 파라미터 삭제를 완화하여 기존의 noise injection regularizer 와 더 유사하게 만들 수 있다. 이를 통해서 pruning의 영구적인 파라미터 삭제가 일반화 성능에 미치는 영향을 알아볼 수 있다.

baseline으로 Prune$_{L}$을 VGG11에 적용하고, $L_{2}$-norm으로 magnitude를 평가했다. 그러고 영구적으로 파라미터를 죽이는게 아니라, 바로 학습에 참여하도록 pruning 알고리즘을 수정했다. (그림5 상단의 Zeroing1)
그러나, 바로 학습에 참여하는 Zeroing1은 가지치기된 피처 맵이 없는 상태에서 가지치기되지 않은 피처를 학습하게 하는 가지치기 노이즈와 다르다.
pruning noise의 regularizing측면의 효과를 유지하기 위해, weight를 0으로 두고 50, 1105 batches만큼 유지했다. 관련 실험으로 weight에 Gaussian nise를 한 번(가우시안 1) 또는 여러번에 걸쳐서 (50, 1105 batches) 반복적으로 추가하는 것의 영향을 측정했다. (그림5의 아래)
만약, 적은 파라미터로 인한 capacity 감소가 pruning으로 인한 일반화성능에 영향을 미치는 것이 아니라면, 일시적으로 pruning noise를 주입하는 알고리즘의 일반화가 Prune$_{L}$의 일반화 동작을 흉내내는 것이라고 예상할 수 있다. 만약, 더 적은 weights가 pruning-based generalization improvement에 필수적인 요소라면 Prune$_{L}$의 일반화 현상과 temporay pruning noise injection 사이에 유사성이 없다고 생각해도 될 것이다.
pruning noise injection이 pruned DNN에서 일반화 성능을 높인다는 아이디어에 따라서, zeroing 50을 사용했을때 Prune$_{L}$과 상당히 유사한 최종 일반화 성능을 보인다. 실제로 훈련 전반에 걸쳐 두 방법 모두 비슷한 수준의 불안정성과 테스트 정확도를 보였다. (그림5의 상단) 이러한 결과는 Overparamterized DNN의 pruning-based generalization improvements가 파라미터 개수를 감소시킬 필요로 하지 않는다는 것을 말한다.
최종적으로, 학습중에 Gaussian noise를 파라미터에 대해서 여러번 추가했을때의 영향에 대해서 평가했다. generalization-stability tradeoff에 따라 Gaussian noise가 충분히 긴 기간 동안 추가되었을 때(Gaussian1105, 그림5의 하단) 성능이 크게 향상되는 것을 확인했다. 이 결과는 generalization-stability tradeoff가 pruning에만 적용되는 것은 아니고, pruning noise injection이 그냥 노이즈의 한 특수한 경우일 뿐이라는 결론이 난다.
Flatness: a mechanism for pruning-based generalization improvements?
Representations에 noise pruning을 추가하면 최종 모델이 일반화 성능이 높은 flatness 모델이 되게 할 수 있을까?
Noise injection의 성공 사례와 pruning이 Dropout과 관련이 있다는 논문들을 보고, pruning noise가 최종 모델의 일반화에 도움이 되는 flatness를 만들수 있지 않을까? 하는 가정을 했다.
특히, 더 큰 노이즈를 도입하는 불안정한 pruning이 데이터 샘플 및 매개변수(flatness)의 변화에 대한 모델 견고성을 높일 것으로 예상했다.
또한, flatness가 높을수록 일반화가 높아진다는 경험과 이론에 따라 flatness가 Overparameteriezd DNN의 일반화에 도움이 될 것으로 예상했다.
또는 pruning 안정성과 일반화가 상관관계가 있을 수도 있고, pruning noise가 flatness와 무관한 방식으로 도움이 될 수도 있고, flatness 차이가 pruning 일반화 이점을 설명하지 못할 수도 있다.
이러한 가설을 테스트하기 위해 flatness에 대한 몇 가지 측정값을 계산하고 VGG11에서 pruning 안정성 및 최종 일반화와의 관계를 조사했다. 안정성이 감소하면 모든 flatness 측정값의 최소값이 더 평탄해지기 때문에 flatness 안정성 사이에도 상충 관계가 있음을 발견했다(그림 6).

또한 flatness가 증가하면 일반화가 개선되었다. 따라서 pruning 안정성이 낮을수록 일반화에 도움이 되는 종류의 flatness가 높아진다는 가설을 뒷받침하는 증거를 발견했다.
이 결과는 또한 우리가 관찰한 generalization-stability tradeoff가 수렴된 솔루션의 flatness 증가에 의해 매개될 수 있음을 의미한다.
특히, DNN이 pruning으로 인한 representation의 손상으로부터 회복된 후에는 일반화가 더 잘 될 뿐만 아니라 데이터 샘플 및 매개변수 변경에 덜 민감진다. pruning을 noise injection으로 취급하는 것을 뒷받침하는 이 flatness 효과는 불안정한 pruning에 의해 강화된다.
더 넓게 보면, flatness가 DNN의 일반화 수준을 설명할 수 있음을 보여주는 최근의 경험적 증거에 더해진다.
또한 일반화 성능을 이해하기 위해 gradient 공분산을 살펴보는 것이 도움이 된다는 최근의 실험을 뒷받침한다.
마지막으로, 이러한 발견은 pruning이 일반화 성능을 향상시킨다는 관찰과 매개변수 수의 역할을 강조하지 않거나 제거하는 새로운 일반화 이론 사이의 모순을 해결한다.


