Neurips 2021, Tsinghua University
https://arxiv.org/abs/2110.14430
Adversarial Neuron Pruning Purifies Backdoored Deep Models
As deep neural networks (DNNs) are growing larger, their requirements for computational resources become huge, which makes outsourcing training more popular. Training in a third-party platform, however, may introduce potential risks that a malicious traine
arxiv.org
Network를 학습시킬때 필요한 데이터량과 계산량이 증가하면서, MLaaS platform에 맡기거나, pretrained model을 다운받는 경우가 많다. 이러한 경우에, "backdoor attack" 위험이 생길 수 있다.
"Backdoor attack"이란, 학습과정에서 데이터셋에 trigger pattern <-> target label 간의 관계를 강하게 만들 수 있도록, 일부 데이터를 추가하여 학습하는 것을 말한다.
누군가 악의적으로 특정 상황에서 잘못 분류를 하도록 backdoored Deep Models을 학습시켰다고 가정해보자.
"특정상황"에 대한 조건을 모르면, 이 network가 backdoored Deep Model인지 구분하기도 어렵고, 복구도 어렵다.
이러한 공격을 받은 network는 정상적인 데이터를 받았을때는 잘 작동하지만, trigger pattern이 들어왔을때, misclassification된다.

기존에도 이를 막는 방법들이 있었는데, 이는 training과정에서 할 수 있는 방법들이 대부분이었기에 robustness에 한계가 있었다.
- MLaaS service나 pretrained model의 경우, training과정에 간섭할 수 없기 때문이다.
data trigger말고도, neurons에 아주 작은 숫자를 곱해서, weight를 바꿔서 classification loss가 올라가 misclassification하도록 할 수 있는데, 이 perturbation budget에서 backdoored network가 일반 network보다 더 빠르게 망가지고, 더 쉽게 target label(trigger label)을 내는 경향이 있다는 것을 저자들이 발견했다.
이 내용을 바탕으로, adversarial neurons perturbation중에 가장 sensitive한 neurons를 pruning하는 ANP를 제시했다.
- resnet18에는 4810개의 neurons가 있는 반면에, 파라미터는 11M(1100만) 개가 있다.
- pruning하는 대상이 parameter가 아니라, neurons라서, 1%정도의 clean data만으로도 충분히 잘 동작한다.
contribution은 다음과 같다.
- adversarially perturbing neurons에서 backdoored DNNs이 normal DNNs보다 trigger patterns없이도 더 misclassification을 하게 된다는 점을 발견했다.
- 단순하지만 효과적인 repairing method, ANP를 제안했다.
- 실험을 통해서 ANP가 SOTA급 defense 성능을 보였다.
Methods
cnn등 다양한 구조에도 적용할 수 있지만, fc를 예시로 들었다.
layers가 $0$ (input layer)부터 $L$ (output layer)까지 있고, 각 layer는 $n_{0}, \cdots , n_{L}$ 개의 neurons로 구성되어있다고 가정할때 network의 총 neurons 수는 $n_{1} + \cdots + n_{L}$과 같다.
$l$번째 layer의 $k$번째 neuron의 weight parameter를 $w_k^{(l)}$, bias를 $b_{k}^{(l)}$이라고 할때 output은 다음과 같다.
$h_{k}^{(l)}$ = $\sigma ( w_{k}^{(l)\top} h^{(l-1)} + b_{k}^{(l)} )$
$\sigma$는 비선형함수, $h$는 이전 layer에서 모든 neurons의 outputs을 말한다.
이 논문에서는 $l$번째 layer의 $k$번째 neurons이 주어졌을때, $w_{k}^{(l)}$와 $b_{k}^{(l)}$를 바꿔서 misclassification을 만드는 방법으로 사용한다. 각 weight와 bias마다 아주 작은 값을 각각 준비하여 크기를 변화시킨다.


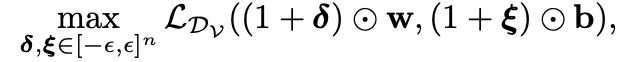

그림1의 a)를 보면, adversarial neuron perturbations의 budget $\varepsilon$ 가 커질수록 misclassification이 증가하는 것을 볼 수 있다. 또한 정상인 benign모델과 비교했을때, 어느 $\varepsilon$에서도 backdoored models (BadNets, IAB)의 error rate가 크다.
그림1의 b)를 보면, adversarial neuron perturbations로 정상 모델은 class3을 output으로 잘못 판단했는데, backdoored model은 모두다 target class0으로 잘못 판단했다. 이를 통해서 backdoor에 사용된 trigger를 모르더라도, backdoor행동을 유발할 수 있다.
$l$번째 layer에 $k$번째 neuron이 backdoor와 관련있다고 가정해보자. backdoor neuron은 clean data에 대해서 반응하지 않을 것이다.
만약 해당 layer에서 w와 b를 연산한 값이 0보다 크다면, $w$와 $b$이 커질 수록 결과값도 커질 것이다.
이때, 반응하지 않던 backdoor neuron이 활성화된다. 이러한 변화가 제일 큰 것이 backdoor와 밀접한 관련이 있을 가능성이 크다.
위에서 언급한 관련성을 기반으로, sensitive neurons를 pruning하여 제거한다. 이때, clean data 정확도 손실을 막기위해 bias는 프루닝하지 않는다.
projected gradient decent(PGD)를 사용해서 mask threshold를 optimize했다.

$\alpha$값이 1에 가까워지면, pruned model이 clean data에 잘 맞추도록 학습하고, 0에 가까워지면, backdoor attack에 강해지도록 학습한다.

ANP의 알고리즘에 대해서 정리하자면 다음과 같다.
- unpruned network를 초기화하고, 모든 mask를 1로 초기화한다.
- perturbation 입실론 값도 uniform distribution에서 랜덤으로 초기화한다.
- 한 step 한다.
- ANP로 얻은 mask value를 업데이트하고, [0, 1]값으로 만든다.


