
둔비의 공부공간
Can Bad Teaching Induce Forgetting? Unlearning in Deep Networks Using an Incompetent Teacher 본문
Can Bad Teaching Induce Forgetting? Unlearning in Deep Networks Using an Incompetent Teacher
Doonby 2023. 10. 5. 19:59Unlearning이라는 새롭게 접한 분야의 논문이다.
AAAI 2023에 Accepted 됐다.
https://arxiv.org/abs/2205.08096
https://github.com/vikram2000b/bad-teaching-unlearning
GitHub - vikram2000b/bad-teaching-unlearning: Official repo of the paper Can Bad Teaching Induce Forgetting? Unlearning in Deep
Official repo of the paper Can Bad Teaching Induce Forgetting? Unlearning in Deep Networks using an Incompetent Teacher accepted in AAAI 2023 - GitHub - vikram2000b/bad-teaching-unlearning: Officia...
github.com
Abstract
Data privacy로 인해 Machine unlearning이 많이 연구되고 있다.
이미 학습된 ML model에서 scratch부터 학습할 필요없이 특정 데이터를 제거하는 것이 Machine unlearning의 목표이다.
논문의 저자들은 두가지의 teacher model을 구축해서 student가 잊을 수 있도록 유도하는 machine unlearning 방법을 제안했다.
- 유능한 teacher / 무능한 teacher로 두가지 모델을 사용한다.
또한, unlearning method에 적용가능한 zero retrain forgetting (ZRF)라는 새로운 metric을 제안했다.
기존 metric과 다르게, ZRF 점수는 비싼 retrained model을 사용할 수 있는가?에 의존하지 않는다.
Random subset forgetting과 class forgetting을 다양한 networks와 application domain에 대해서 실험도 진행했다.
Introduction
Unlearning methods는 아래 내용에 대해서 적용이 가능하다.
- single class or multiple class를 잊게 한다.
- single class의 특정 집단을 잊게 한다.
- multiple classes에 대해서 random subset을 잊게 한다.
이 논문에서는 knowledge distillation를 사용하여 위 3가지 방법에 적용 가능한 robust unlearning method를 제안했다.
또한, 2021년에 unlearning method가 개인정보유출을 만들 수 있다는 연구도 있었기 때문에, membership inference attack같은 privacy attacks에 얼마나 취약한가? 도 검증해야한다고 말한다.
그러므로 저자들은 unlearning method들의 일반화 성능을 평가할 수 있는 새로운 metric도 제안했다.
기존의 unlearning method들은 mixed-linear model을 학습해야하거나, SGD만을 사용해야하는 등의 constraints를 필요로 했었다.
하지만, 저자들의 방법은 unlearning을 위해 추가적인 모델을 학습할 필요가 없다.
저자들은 computational cost의 기존 방법보다 효율적이고 빠르게 하는 것을 목표로 했다.
핵심 Contribution은 다음과 같다.
- 유능/무능한 teacher로 구성된 teacher-student framework을 제안하여, single-class와 multiple class unlearning에 모두 적용할 수 있으며, 효과적으로 multiple class random-subset forgetting도 된다.
- ZRF라는 robustly하게 unlearning method를 평가하는 metric을 제안했다. forget data에 대한 일반화 성능을 평가한다.
- CNN, Vit, LSTM등 다양한 모델에 적용이 가능하며, 학습할때 필요한 제약사항이 없다.
Related Work
Unlearning in the Deep Networks
기존 방법들은 학습할때 SGD를 활용해서 "scrubbing method"로 정보를 지우거나 mixed-linear를 추가해서 original model과 함께 학습했었다. 이는 너무 큰 computational costs를 필요로 하고, 학습과정에 제약이 있었으며, approximation method에 대한 한계도 있었다.
Tarun et al(2021)은 좀 더 효율적인 class-level machine unlearning method를 제안했으나, random subset forgetting은 지원하지 않았다.
Preliminaries
complete dataset Dc={(xi,yi)}ni=1
number of samples : n
ith sample : xi
coreesponding class label : yi
set of samples to forget : Df
remain samples : Dr
unlearning label : lu , 1이면 Df, 0이면 Dr에 해당함.
(In class-level unlearning)
Df는 하나 혹은 여러 class에 존재하는 모든 데이터 samples
(Random-subset unlearning)
Df는 하나 혹은 여러 class의 데이터 샘플중 random subset으로 구성되어있음
forget samples정보 없이 scratch부터 학습한 모델 : retrained model or gold model
fully trained model or original model : competent teacher (Ts(x;θ) trained data Dc)
incompetent teacher는 randomly initialized model.
student model은 teacher model과 parameter가 동일하게 시작함. (S(x;θ))
Proposed Method
Unlearning with Competent/Incompetent Teachers
competent teacher, incompetent teacher, student model 로 총 3가지의 모델을 사용한다.
최종적인 목표는 student model에서 forget sample의 information만 골라서 지우고, retain set의 성능은 보존해야한다.
즉, Df는 잊고 Dr은 기억하는 것이 unlearning의 목적이다.

Dr은 기존의 Dc로 학습한 competent teacher에게 주어 logit을 구하고
Df는 random init된 incompetent teacher에게 주어 random logit을 구한다.
각 logit을 KD로 받으면서, Df에 대한 정보를 없애는 방법이다.
이때 아예 acc를 0으로 만드는게 아닌 random guess하도록 만드는데, 이러한 작업이 forget sample에 대한 정보 유출의 위험을 방지해준다고 한다.


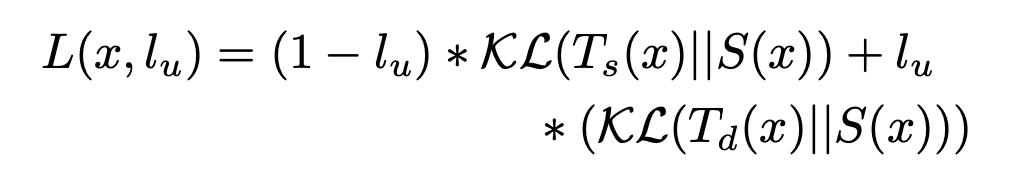
Zero Retrain Forgetting Metric
acc외의 기존에 사용하던 metric은 학습을 처음부터 다시 해야 측정이 가능하다는 문제가 있었다.
단순하게 Dr와 Df의 성능을 측정하는 것은 실제로 해당 정보가 지워졌는가?에 대한 판단은 불가능했다.
이러한 문제들을 피하기 위해, 저자들은 retrained model에 의존하지 않는 'Zero Retrain Forgetting Metric'을 제안했다.
이는 incompetent teacher Td와 비교하여 model의 random-ness를 측정하는 방법이다.
"Jensen-Shannon divergence"를 사용하여 unlearned model M과 incompetent teacher Td를 비교한다.
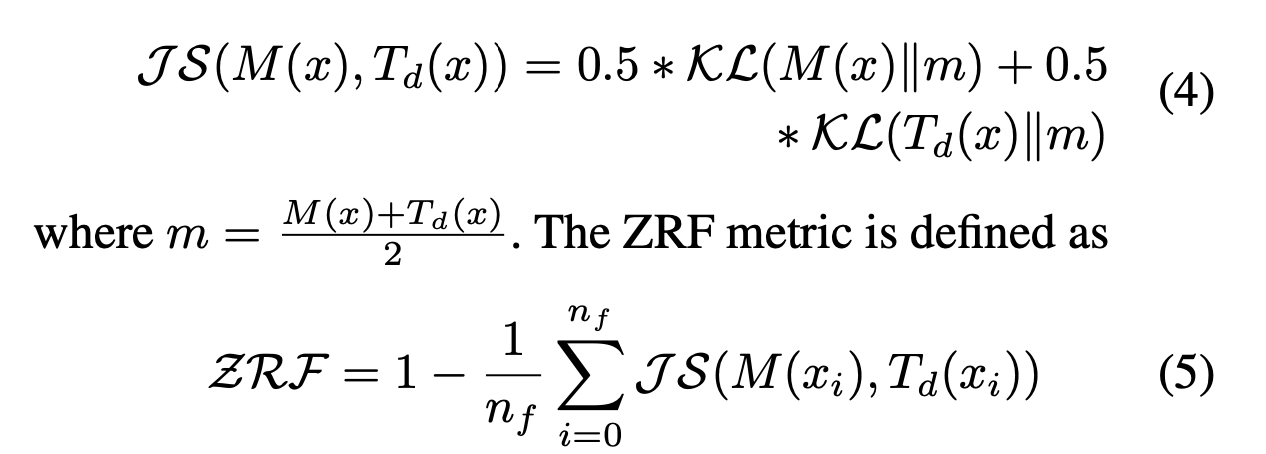
이때, xi는 Df의 i번째 데이터를 말한다.
ZRF점수는 0~1사이로 나오게 된다. 1에 가까워질수록 완벽하게 forgetting sample에 대해 random guess를 하는 것이고
0에 가까워질수록 특정 pattern이 존재한다는 뜻이다.
하려고 하는 task는 특정 class의 sample을 지웠을때, 해당 class의 일반화 성능이 떨어지는 것이 아니라, 해당 sample에 대해서만 틀리도록 하는 것이 목표다.
이때, 특정 sample에 대한 output이 매번 다르게 나온다면 ZRF의 값은 1이 된다.
하지만 ZRF의 값이 0이라면 해당 sample이 들어올때마다 특정 class로 분류한다는 뜻이다.
이렇게 생각하면 1이 좋은 결과라고 생각할 수 있으나, unlabeled model은 해당 데이터만 없어진것이지 일반화성능이 떨어지는 것을 원하는게 아니기 때문에, 1도 좋은 결과가 아니다. 해당 데이터가 없이 학습했을때 정도의 성능은 나와줘야한다.
이상적인 ZRF 값은 특정 sample없이 처음부터 학습한 모델의 값이 좋은데, 이렇게 학습하는 것은 논문의 목표와는 다르기 때문에 불가능하다.
그렇기에 test dataset를 사용하여 ZRF값을 구하고, 이에 맞춰서 사용한다.
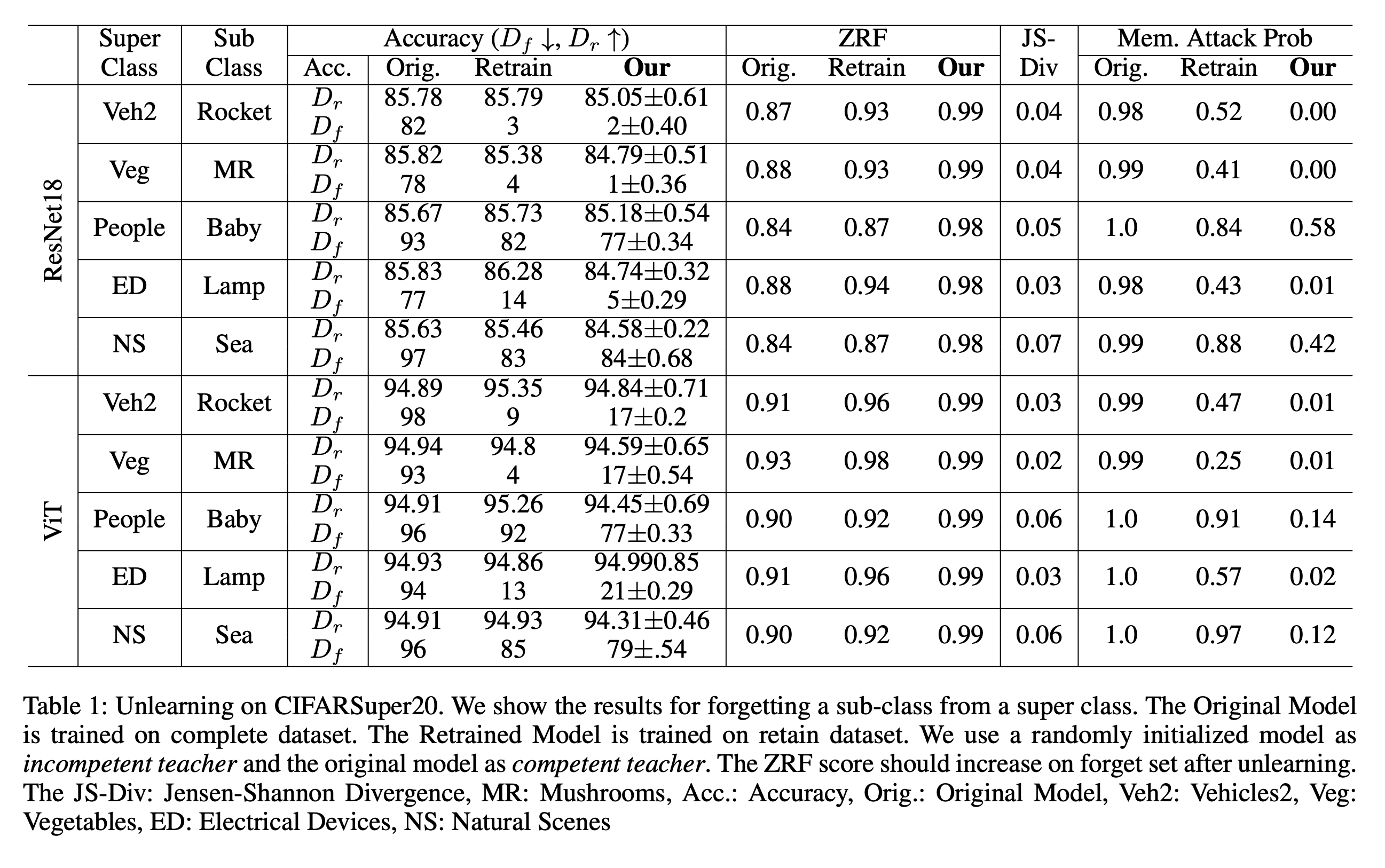
Experiments



'Papers > Others' 카테고리의 다른 글
| Do We Need Zero Training Loss After Achieving Zero Training Error? (0) | 2023.03.15 |
|---|
