https://arxiv.org/abs/2310.19444
One-for-All: Bridge the Gap Between Heterogeneous Architectures in Knowledge Distillation
Knowledge distillation~(KD) has proven to be a highly effective approach for enhancing model performance through a teacher-student training scheme. However, most existing distillation methods are designed under the assumption that the teacher and student m
arxiv.org
https://github.com/Hao840/OFAKD
GitHub - Hao840/OFAKD: PyTorch code and checkpoints release for OFA-KD: https://arxiv.org/abs/2310.19444
PyTorch code and checkpoints release for OFA-KD: https://arxiv.org/abs/2310.19444 - Hao840/OFAKD
github.com
NeurIPS 2023 Poster Accept
Abstract
Feature distillation은 large teacher network의 representation을 student에게 힌트를 주는 방법으로, KD분야에서 많이 사용되어 왔다.
하지만, 논문의 저자들은 CKA(centered kernel alignment)로 feature간의 유사도를 측정한 결과, teacher와 student의 architecture 차이에서 오는 불일치 문제가 존재한다는 것을 확인했다.
이러한 불일치한 feature를 matching하는 것은 효과적이지 않다고 주장하며, 저자들은 feature를 logits space로 embedding하여 distillation 하는 방법을 제안했다. 추가적으로, 기존의 KL Divergence loss를 약간 수정하여, teacher의 target에 대한 confidence가 높을수록 kl loss의 영향을 크게 하는 adaptive target enhancement scheme을 제안했다.
이러한 방법을 통해서 CIFAR100에서 최대 8.0%, ImageNet에서 0.7%의 성능향상을 보였다.
Methods

(CKA는 CKA에 대해서 정리가 잘 된 블로그 참고 (링크))
서로 다른 아키텍쳐의 feature similarity를 구한 그림이다.
위 그림을 보면 CNN/CNN, ViT/ViT, MLP/MLP의 CKA는 비슷하지만, CNN/ViT, ViT/MLP, CNN/MLP의 similarity는 다르게 보이는 것을 볼 수 있다.
저자들은 이러한 상황에서 feature(hint-based) distillation를 주는 것은 크게 도움이 되지 않는다고 말한다.
feature distillation을 사용하지 않고, logits distillation만 사용하면 위의 문제를 해결할 수 있지만, suboptimal result로 이어질 수 있다고 한다.
이를 해결하기 위해, feature를 logits으로 embedding하는 aux branch(inference할땐 제거)를 추가하여, logits distillation으로 해결한다.

추가로, Adaptive target information enhancement 를 제안하는데, 다른 모델의 다른 inductive bias로 인한 prediction 결과에 대해서 보정하기 위해서 teacher가 정답을 맞췄을때(정답에 가까운 confidence일때) 더욱 강력하게 Kl divergence를 주고, teacher가 정답을 틀렸을때(정답과 먼 confidence를 가졌을때) kl divergence의 영향을 줄이는 loss term을 제안한다.

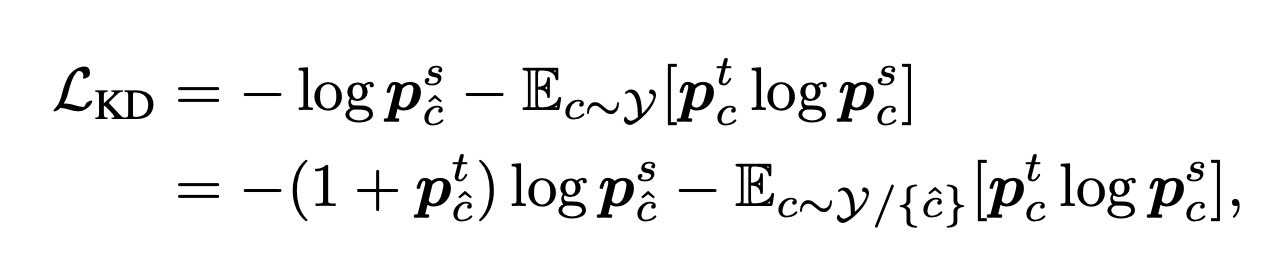

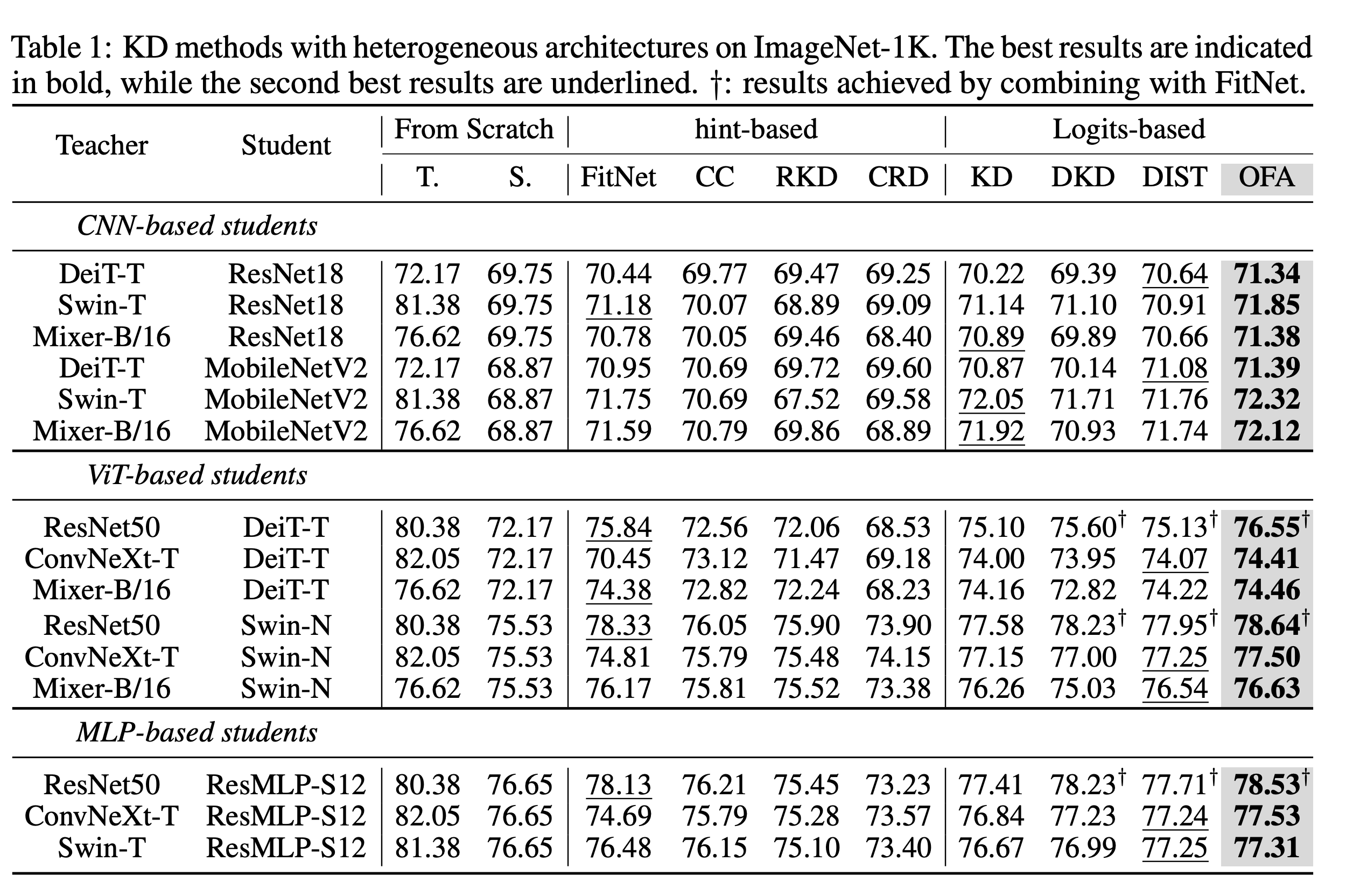
Experiments

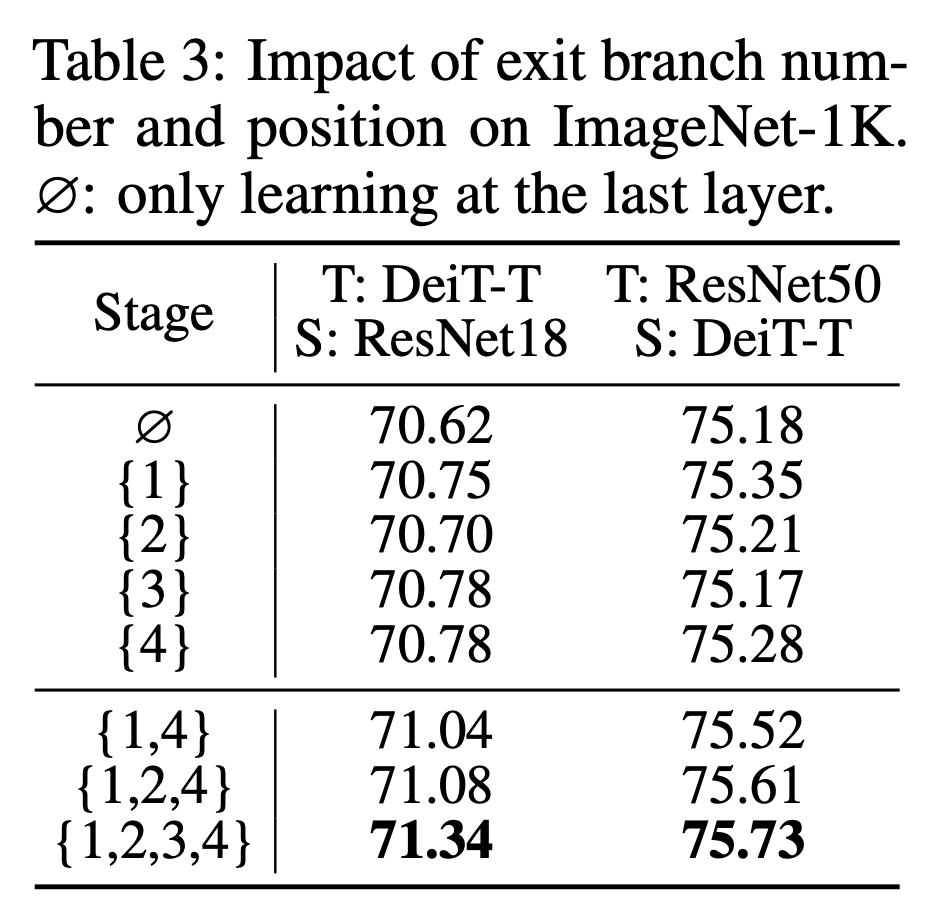
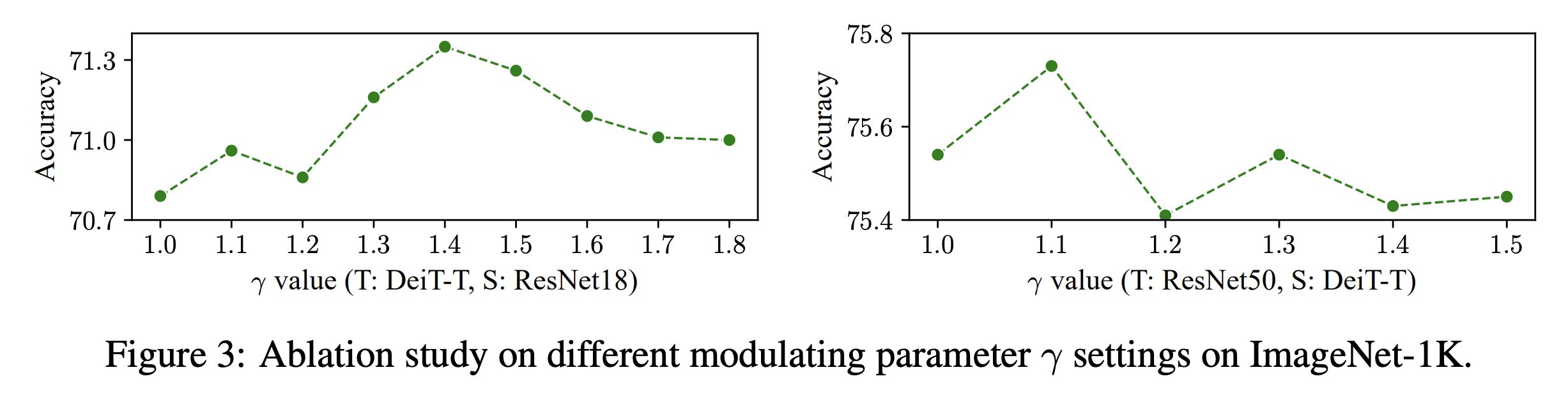
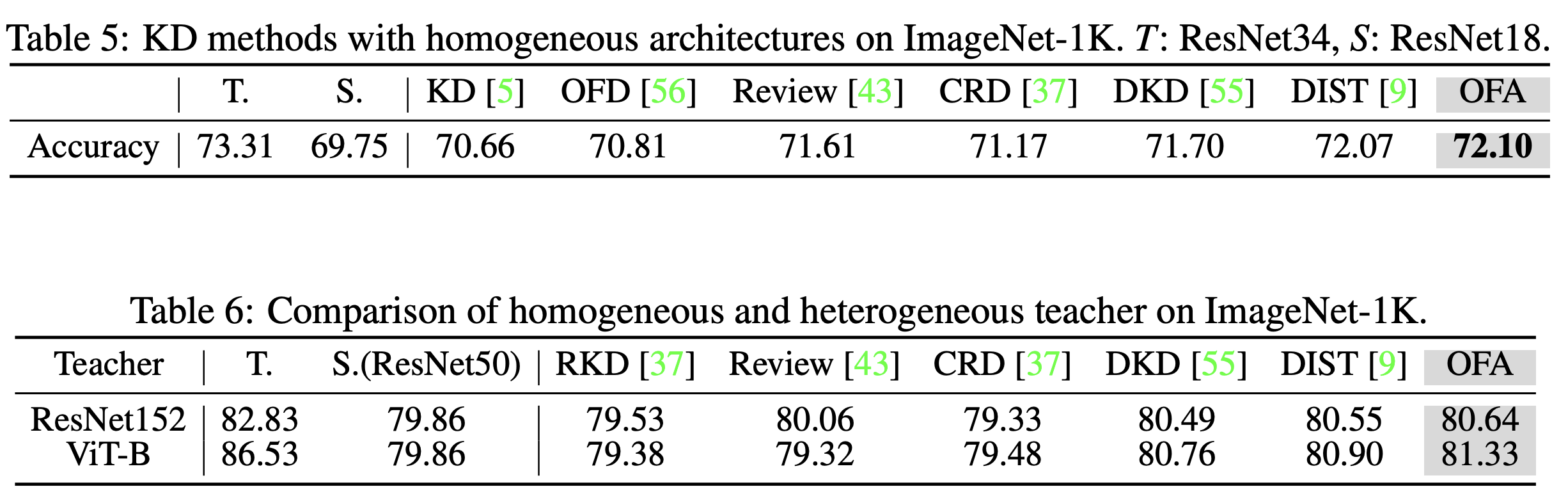
Conclusion
이 논문은 "서로 다른 architecture에서 hint-based knowledge를 어떻게 distill하는 것이 좋은가?" 에 대한 분석을 진행했다.
CKA를 통해 서로 다른 archutecture는 representation 간에 gap을 갖고 있고, 논문에서 제안하는 one-for-all(OFA)를 통해 이 차이를 줄일 수 있었다.
또한, KD loss의 형태를 재구성한 adaptive target information enhancement를 제안하여 teacher의 확신에 따른 loss의 변화를 주었다.
이러한 방법으로 CIFAR100과 ImageNet에서 높은 성능을 달성했다.
(논문을 보고 든 사견)
Teacher의 confidence에 따른 Knowledge distillation loss를 변경하는 것은 예전에 고민한적이 있으나,
CIFAR에서는 쉬운 데이터셋에 큰 teacher의 영향으로, teacher의 confidence가 너무 높아서 큰 의미를 발견하지 못하고 넘어갔다.
이 논문을 읽고 새로운 아이디어를 고민하고 있는데, 좋은 결과로 이어졌으면 좋겠다.
'Papers > Compression' 카테고리의 다른 글
| Scale Decoupled Distillation (0) | 2024.05.16 |
|---|---|
| Cumulative Spatial Knowledge Distillation for Vision Transformer (0) | 2024.04.11 |
| Class Attention Transfer Based Knowledge Distillation (0) | 2024.02.25 |
| Curriculum Temperature for Knowledge Distillation (0) | 2023.12.28 |
| Multi-level Logit Distillation (1) | 2023.12.08 |