https://arxiv.org/pdf/2502.02631
https://github.com/facebookresearch/ParetoQ
GitHub - facebookresearch/ParetoQ: This repository contains the training code of ParetoQ introduced in our work "ParetoQ Scaling
This repository contains the training code of ParetoQ introduced in our work "ParetoQ Scaling Laws in Extremely Low-bit LLM Quantization" - facebookresearch/ParetoQ
github.com
NeurIPS 2025에 올라온 Meta AI의 low-bit quantization 논문입니다.
Abstract
사람들은 '4bit가 좋다', '아니다 1.58bit가 좋다' 등 다양한 의견 차이를 보이고 있습니다.
하지만 이런 다양한 bit를 통합해서 비교하는 프레임워크가 없었기에, 명확한 결론이 나지 않습니다.
이를 해결하기 위해, 다양한 양자화 설정을 비교할 수 있는 ParetoQ라는 새로운 프레임워크를 제안하여 실험한 결과, 3bit 이상에서는 사전 훈련된 분포를 잘 유지하지만, 2bit 이하에서는 분포가 완전히 변하는 것을 확인했습니다.
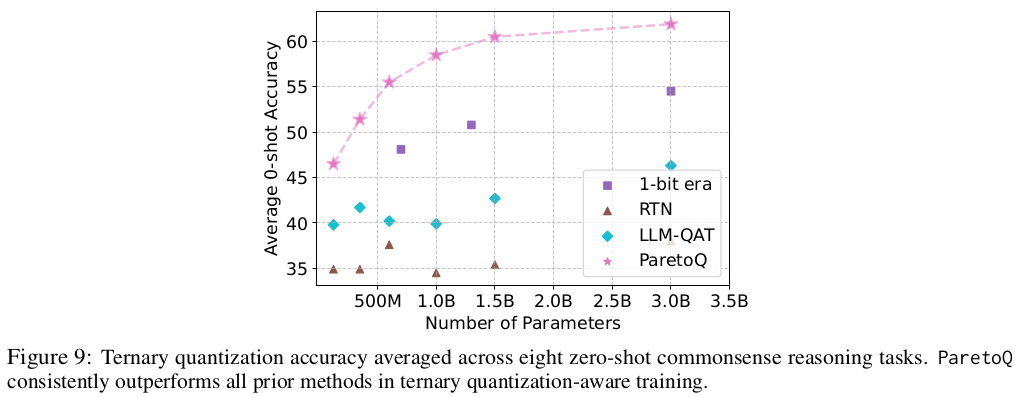
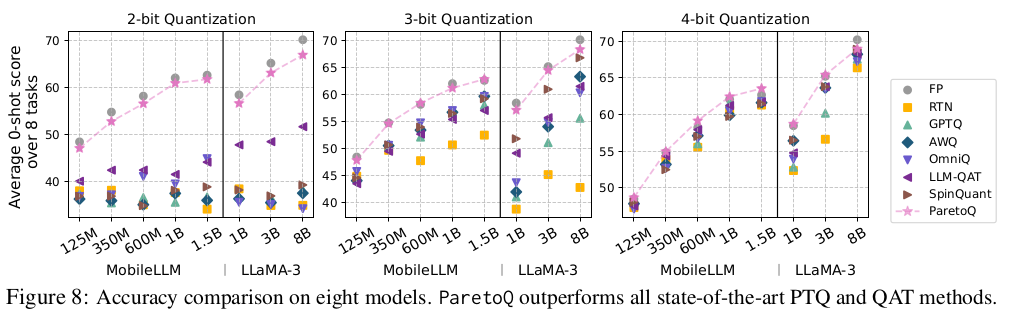
추가적인 실험을 통해서, ternary, 2bit, 3bit가 1bit와 4bit quantization보다 acc와 size간의 tradeoff가 좋았으며, 하드웨어를 고려했을 때는 2bit quantization이 제일 효율적임을 확인했습니다.
1. Introduction
"Bit를 낮춘 만큼 모델 크기를 키울 수 있는데, 과연 적절한 bit와 모델 크기는 어떻게 될까?"
이러한 질문에 대해서 일부 연구에서는 4 or 6bit quantization이 제일 적절하다고 이야기하고, 다른 연구에선 1.58bit quantization도 적절하다고 이야기합니다.
bit만 같지, 서로 다른 quantization function과 학습 방법들을 사용했기 때문에 이 연구들을 제대로 비교하기는 어렵습니다.
이러한 이유로 논문의 저자들은 정확한 비교를 위해, 각 bit에 대해 최적의 학습 및 양자화 설정을 먼저 찾아야 한다고 주장합니다.
정확한 비교를 위해서 token 개수 ($D$), 모델 파라미터 ($N$), precision ($P$) 뿐만 아니라, 학습 방법 ($S$), qunatization function ($F$)를 추가합니다.
총 다섯가지 차원에서 분석했을때, 아래와 같은 사실들을 발견했습니다.
- Binary Quantization은 정확도를 크게 망친다.
- 1.58, 2, 3 bit quantization은 서로 비슷한 성능을 보이고, 종종 4bit보다도 좋을 수 있다.
- 3~4bit 이상에서는 FP에서 weight를 살짝 바꾸면서 quantization error를 잡지만, 2bit 이하에서는 아예 재구축을 한다.
- 2bit이하에서는 quantization grid와 quantization range에 매우 민감하다.
2.1 Training Budget Allocation
QAT는 $\beta_{FPT}$ (Full Precision Training) + $\beta_{QAT}$ QAT 로 나눌 수 있는데, 이 학습 비율은 어떻게 하는 것이 좋을까?
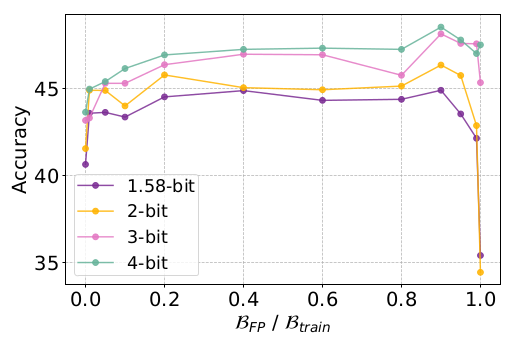
위 그림은 MobileLLM-125M 모델로, 1.58, 2bit의 경우 1.0 (PTQ)를 했을때 성능이 크게 떨어지는 것을 볼 수 있습니다.
이 실험을 통해서 약 90%의 tokens으로 full precision 학습을 하고, 10%의 tokens로 QAT를 하는 것이 제일 좋은 방법이라고 말합니다.
2.2 Finetuning Characteristics
- Binary, ternary를 포함한 모든 bit에서 full precision pretrained가 좋았습니다.
- Lower bit quantization (binary, ternary, 2-bit)는 higher bit quantization (3-bit, 4-bit)보다 더 많은finetuning을 필요로 합니다.
- Lower bit quantization은 약 30B tokens, Higher bit quantization은 10B tokens에서 수렴합니다.
- Finetuning후 Higher bit quantization은 full-precision accuracy 근처로 회복하지만, Lower bit quantization은 full acc 도달 전에 수렴합니다.
- 이러한 이유는 QAT할때 Lower bit는 weight reconstruction에 가깝고, Higher bit quantization은 compensation에 가까워서, Lower bit quantization에서는 한계가 있습니다.

3.1 Preliminary

- Quantized weights : $W_{q}$
- Real-value weights : $W_{R}$
- Scale $\alpha$, Bias $\beta$ -> symmetric min-max와asymmetric min-max quantization에 따라 값이 다릅니다.
- 4bit이상에서는 symmetric min-max quantization만으로도 충분하지만, lower bit quantization에서는 다른 함수가 필요합니다.
- Binary quantization에서는 $W_{R}$의 부호만 가져다가 $W_{B}$로 사용하는게 일반적입니다.
- Ternary quantization에서는 threshold $\Delta$보다 크면 +$\alpha$ or -$\alpha$로 두고, 작으면 0으로 만드는 방법을 사용합니다. ($alpha$값은 0아 아닌 $W_{R}$의 평균값을 사용하는게 일반적)
- 하지만, 2bit나3bit에 적합한 quantization function은 없고, min-max quantization을 사용하면 큰 정확도 손실이 발생합니다.
3.2 Introducing ParetoQ
저자들은 LLM low-bit quantization에서 두가지 중요한 trade-off가 있다고 이야기합니다.
Outlier precision vs intermediate value precision

- 양자화를 outlier에 집중하면, 큰 $W_{R}$는 표현이 잘 될 수 있지만, 0에 몰려있는 대부분의 $W_{R}$의 양자화 해상도는 떨어질 수 밖에 없습니다.
- 이러한 현상은 extremely low bit quantization에서 min-max quantization을 사용하면 심하게 발생합니다.
- 위 Figure 6 (b) ~ (e)를 보면, min-max range는 4bit에서는 잘 되지만, 그 이하에서는 정확도가 크게 떨어지고, clipping range는 lower-bit에서는 잘 되지만, 4 bit에서는 min-max보다 낮습니다.
Symmetry vs inclusion of "0" at the output level
- [-a, -b, b, a]로 하면 이쁜데, 0인 불필요한 weight들이 -b나 b까지 올라오고, 0을 포함하면 [-a, 0, a, b]로 균형이 깨지는 문제가 있습니다.
이런 문제를 해결하기 위해서 저자들은 LSQ를 수정한 Stretched Elastic Quant (SEQ)를 제안합니다.


Quantization Function

- 1 bit에서는 Elastic Binarization
- 1.58bit와 2bit에서는 SEQ
- 3bit와 4bit에서는 LSQ를 사용했다.
- $ n = -2^{N_{bit} -1}$ and $p = 2^{N_{bit}-1} -1$

4.2 Hardware Implementation Constraints
1.58 bit는 이론적으로는 2bit보다 더 좋은 저장 효율을 보이는 것 같지만, 실제 구현에서는 비효율적입니다. (sparsity가 90%가 넘을때만 효과적)
반면, 2-bit quantization은 bit pairs를 값에 직접 매핑할 수 있기 때문에, unpacking과 conversion overhead를 줄일 수 있습니다.
커스텀 GEMM 커널 구현이 있으면, 실제 배포를 위한 선택지로서 더 실용적일 것이라고 이야기합니다.
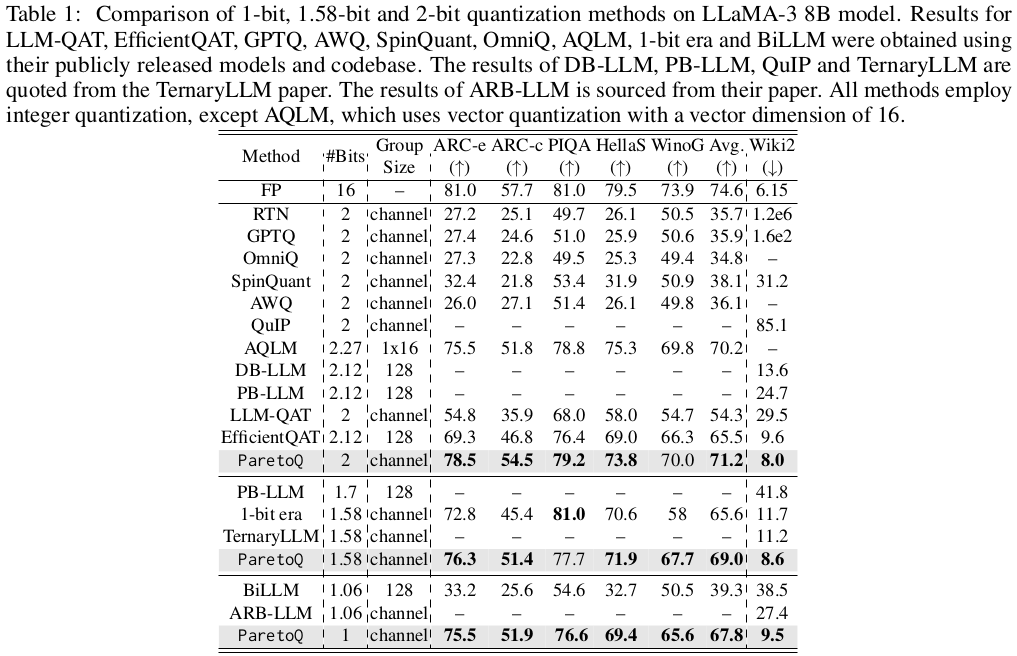
5. Experiments
MobileLLM-125M/350M/600M/1B/1.5B, LLaMA3-1B/3B/8B
Evaluation : 8 zero-shot commonsense reasoning tasks and Wiki2 test set.