ICLR 2022
https://arxiv.org/abs/2106.14568
Deep Ensembling with No Overhead for either Training or Testing: The All-Round Blessings of Dynamic Sparsity
The success of deep ensembles on improving predictive performance, uncertainty estimation, and out-of-distribution robustness has been extensively studied in the machine learning literature. Albeit the promising results, naively training multiple deep neur
arxiv.org
Abstract
최근 efficient ensemble 방법들은 적은 cost로 기존 ensemble performance에 도달했다.
그러나, training resources는 여전히 single dense model을 학습하는 것과 거의 비슷하다.
Dynamic Sparse Training을 제외한 sparse network를 scratch부터 학습하는 방법은 대부분 network pruning보다 성능이 낮았다.
- DST는 dense network의 weight를 상속받지 않고, randomly-initialized sparse network에서 시작해서 optimizes the model weights와 sparse connectivity를 함께 학습한다.
- 근데, dense network의 performance를 내기 위해서는 훨~씬 많은 epoch로 학습시켜야 가능하다.
이 논문에서는 FreeTickets라는 framework를 제시하여 sparse neural network training과 ensembles간의 연결을 보였다.
dense networks를 여러번 학습하고 average하는 것이 아니라, sparse sub-networks를 direct로 학습하고, 다양한 sub-network를 추출한다.
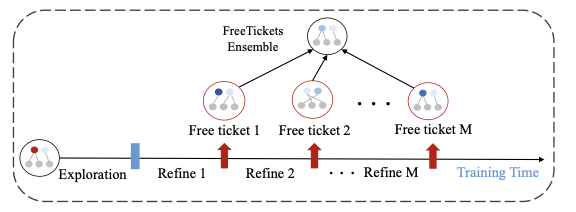
이때 ensemble 성능을 보장하기 위해, free tickets가 필요한 조건이 3개 있다.
- High diversity
- ensemble theroy에 따르면, ensemble member간의 higher diversity가 higher predictive performance를 낸다.
- High accessibility
- 별도의 큰 cost없이, 모델을 얻기 쉬워야한다.
- High expressibility
- 각 free ticket의 성능은 dense model과 견줄만해야한다.
FreeTickets 는 single dense model보다 parameter와 training FLOPs가 적다.
Introduction
Local minima solutions이 high dimensional optimization landscape에 많이 있고, 학습중에 random initialization, random mini-batch shuffling등의 다양한 랜덤성이 있기에, network는 비슷한 error rate의 다른 곳으로 수렴하게 된다.
Deep ensembles은 이 여러 곳으로 수렴한 network들을 결합해서, single network보다 더 큰 성능향상을 낼 수 있게 된다.
하지만, 기존 deep ensemble은 network를 독립적으로 여러번 학습시키고 이를 결합했기 때문에 ensemble member수에 비례하게 training, inference cost가 증가하는 문제가 있었다.
최근에는 효율적인 ensemble이 약간의 overhead를 갖고, dense ensemble의 성능을 거의 따라 잡았지만, 여전히 training resource는 최소 single dense model을 학습하는 만큼 필요했다.
최근에는 성능을 유지하면서, sparse network를 scratch부터 학습하는 방법들이 연구가 됐지만, Dynamic Sparse Training(DST)를 제외하고는 대부분 기존 pruning 방법보다 성능이 낮았다.
Training independent subnetworks for robust prediction
Recent approaches to efficiently ensemble neural networks have shown that strong robustness and uncertainty performance can be achieved with a negligible gain in parameters over the original network. However, these methods still require multiple forward pa
arxiv.org
DST는 dense network의 weights를 받아오는게 아니라, random-initialized sparse network에서 시작하고, weight와 sparse connectivity를 함께 학습한다. (network 가중치 공유 비율을 학습한다고 보면 될듯?)
- dense network성능에 도달할 수 있는 방법은 sparse network의 epoch를 늘리는 방법밖에 없다.
이 논문에서는 sparse training과 deep ensemble을 결합하여 위에서 언급한 문제를 해결하려고 한다.
강한 winning ticket을 찾는데에 모든 자원을 할당하는 것 대신에, 매우 낮은 cost로 weak ticket(free tickets)를 찾을 수 있다.
이러한 free tickets를 조합하는 것이 single dense network나 dense ensemble의 성능을 능가할 수 있을까?
더 좋은 ensemble 성능을 보장하려면 3가지의 조건을 만족해야한다.
- Ensemble member간의 "High diversity"가 더 좋은 성능을 낼 수 있게 한다.
- Free tickets는 구하기 쉬워야한다 (low cost).
- 각 free tickets들은 dense model과 정확도를 견줄만 해야한다.
FreeTieckts란, low cost로 구한 정확한 sub-network를 사용하여 ensemble을 수행하는 효율적인 ensemble framework다.
또한, 두 가지의 효율적인 ensemble methods를 사용하여 FreeTickets를 나타냈다.
- Dynamic Sparse Training Ensemble (DST Ensemble)
- Efficient Dynamic Sparse Training Ensemble (EDST Ensembe)
논문의 Contributions을 정리하면 다음과 같다.
- First method, DST Ensemble은 여러 sub-network를 dynamic sparsity로 scratch부터 독립적으로 학습하는 방법으로 좋은 성능을 냈다.
- Second method, EDST Ensemble은 single run에서 많은 free tickets를 생성하여 효율적이고 성능또한 dense ensemble과 유사하다.
- 다양한 subnetwork를 논문의 method들로 생성하고, 논문의 diversity와 효율성에 대해서 확인했다.
- Sparse network가 training/inference 효율성외에도 dense network에 없는 특성 (robustness, out-of-distribution generalization, etc)으로 새로운 연구의 방향성을 제시한다.
Related works
Efficient Ensemble
- Ensemble의 최대 단점은 computational and memory cost가 너무 비싸다는 것이다. 이를 해결하기 위해 다양한 연구들이 진행됐다.
- TreeNet - shares weights in earlier layers and splits the following model into several branches, improving acc over the dense ensemble.
- Monte Carlo Dropout - used to approximate model uncertainty in deep learning without acrificing either computational complexity or test acc.
- Batch Ensemble - proposed to improve parameter efficiency by decomposing the ensemble members into the product of a shared matrix and a rank-one matrix personalized for each member.
- MIMO - use a multi-input, multi-output configuration to concurrently discover subnetworks that co-habit the dense network without explicit separation.
- Snapshot and FGE - discover diverse models by using cyclcal learning rate schedules.
- 그러나, 여전히 training resource는 적어도 single dense model을 학습하는만큼 사용된다.
Dynamic Sparse Training
- sparse network를 sparse connectivity와 weight를 동시에 optimizing하며 scratch부터 학습하는 방법이다.
- DST는 대부분 sparsification을 위해 gating이나 network를 고르는 selector가 필요로 한다.
FreeTickets
DST
- sparse network를 random-initialized하고, sparse level은 $S = 1 - \frac{||\theta_{s}||_o}{||\theta||_o} $ 를 사용한다.
1 - (count(sparse_weight != 0) / count(dense_weight != 0)) 라고 보면 된다. - DST의 목표는 target sparsity S를 갖는 sparse network를 학습이 끝난 후에 만드는 것으로, computational, memory overhead는 거의 static sparse model을 학습시키는 것과 비슷해야한다.
- 대부분 사용하는 exploration heuristics는 prune-and-grow로, p비율로 pruning하고 그 수만큼 regrowing시키는 방법이다.
- prune-and-grow cycle을 반복하면, parameter budget은 유지하면서 더 좋은 sparse connectivities를 찾을 수 있다.
FreeTickets Ensemble
- DST로 만든 sub-network를 사용하는 효율적인 ensemble 방법이다.
- Free tickets은 sparse training 방법으로 수렴된 sub-network를 말한다.
- 이를 결합하여 FreeTickets Ensemble을 진행한다.
- FreeTickets는 Full network에 서로 다른 sparse topologies들이 존재한다는 점에서 영감을 얻었다.
- 각 sub-network들은 scratch부터 학습했기 때문에, memory와 FLOPs가 single dense network보다 적을 수 있다.
DST Ensemble
- DST의 training 효율성과 M sparse networks를 scratch부터 독립적으로 학습한다는 점을 이용해서, random initialized나, random SGD없이도 naive dense ensemble의 diversity를 넘는다.
- DST의 후속 모델인 Rigged Lottery를 사용했다.
- sparse initialization
- sub-network는 ERK로 random initialized한다.
- sparsity $S$는 layer의 neurons, channel의 개수와 conv kernel의 width, height로 구한다.
- model weight optimization
- standard SGD with momentum을 사용한다.
- parameter exploration
- 학습중 $T$ iteration마다 sparse connectivity를 조정하기 위해 exploration을 진행한다.
- $p$ 비율의 작은 weight를 지운다.
- 지워진 애들의 gradient중 $1-p$비율만큼 살려서 업데이트한다.
- $p = 0.5$, $T = 1000$ for CIFAR, $T = 4000$ for ImageNet
- sparse initialization

EDST Ensemble
- DST는 subnetwork의 수만큼 training runs가 선형적으로 증가한다. (왜?)
이를 해결하기 위해 one training run에서 다양한 subnetworks를 만들 수 있는 EDST Ensemble을 제시한다. - one training run에서 다양한 free tickets를 만드는 것은, current local basin을 어케 탈출할 것인가? 가 관건이다.
논문에서는 model topology에 상당한 perturbations를 추가해서 sparse connectivity를 변경시켜, 강제로 탈출하게 만든다고 한다. - 한개의 end-to-end exploration phase, $M$ refinement phase 로 구성된다.
- Exploration phase
- sparse network를 $lr 0.1$ DST로 학습한다.
- sparse connectivity가 좋은 parameter space를 탐색하는 것이 목표라서, $lr$ 이 크다.
- sparse network를 $lr 0.1$ DST로 학습한다.
- Refinement phase
- M개의 티켓을 구하기 위해, training time을 M개로 나눈다.
각 refinement phase에서, $lr = 0.001$로 학습중인 subnetwork가 수렴되면, 현재 current basin을 탈출하기 위해, exploration rate $q=0.8$ 및 $lr = 0.01$을 사용한다. - 위 과정을 원하는 free tickets 개수만큼 반복한다.
- number of free tickets $M = \frac {t_{total} - t_{ex}} {t_{re}}$
- M개의 티켓을 구하기 위해, training time을 M개로 나눈다.
-
Different from DST Ensemble, the diversity of EDST Ensemble comes from the different sparse subnetworks the model converges to during each refinement phase. The number of training FLOPs required by EDST Ensemble is significantly smaller than training an individual dense network, as DST is efficient and the exploration phase is only performed once for all ensemble learners.
- Exploration phase

- pruning해서 sparse network init하고
- 1 ~ exploration까지 SGD로 학습하면서, update interval마다, p% 지우고, 지운애들중 1-p%는 gradient를 흘린다.
- ensemble member마다
- 2의 내용을 반복하여 학습한다.
- member 모델을 저장하고, explortation q% 지우고, 1-q%는 gradient를 흘린다.
Experimental Results



읽을 논문
- Training independent subnetworks for robust prediction
- Rigging the Lottery: Making All Tickets Winners
- Do We Actually Need Dense Over-Parameterization? In-Time Over-Parameterization in Sparse Training
- Diversity Matters When Learning From Ensembles
- Learning both Weights and Connections for Efficient Neural Networks
- Topological Insights into Sparse Neural Networks
- Linear Mode Connectivity and the Lottery Ticket Hypothesis
'Papers > Compression' 카테고리의 다른 글
| Rigging the Lottery: Making All Tickets Winners (0) | 2023.04.21 |
|---|---|
| Linear Mode Connectivity and the Lottery Ticket Hypothesis (0) | 2023.04.14 |
| DSD Survey (0) | 2023.04.12 |
| AC/DC: Alternating Compressed/DeCompressed Training of Deep Neural Networks (0) | 2023.04.11 |
| DENSE-SPARSE-DENSE TRAINING FOR DEEP NEURAL NETWORKS (0) | 2023.04.11 |