
둔비의 공부공간
Complement Sparsification: Low-Overhead Model Pruning for Federated Learning 본문
Complement Sparsification: Low-Overhead Model Pruning for Federated Learning
Doonby 2024. 7. 9. 20:57Federated + Pruning
https://arxiv.org/pdf/2303.06237
AAAI 2023 Accepted
*communication cost : Federated Learning에서 server와 client간의 통신에서 발생하는 overhead를 말한다.
Abstract
Federated Learning은 privacy-preserving distributed deep learning paradigm이다.
하지만, Federated Learning은 computation과 communucation cost가 필요하기 때문에 특히 mobile같은 환경의 장비에겐 부담된다.
기존 Pruning 방법들은 client <-> server간의 낮은 양방향 communication cost, client에서의 낮은 computation cost, 높은 accuracy를 동시에 만족할 수 없었다.
- Federated Learning 특성상 server가 raw data에 접근하여 pruning된 모델을 finetuning 할 수 없기 때문이다. (privacy-preserving 관점에서 server는 client data에 접근할 수 없다.)
논문의 저자들은 server와 client에서 상호보완적이고 협력적인 가지치기를 통해서 communication, computation cost를 모두 낮추고 acc를 향상시킬 수 있는 (Complement Sparsification, CS)를 제안했다.
각 라운드마다 CS는 client에서 params 정보를 받아와서, 이 params로 전체 데이터의 분포를 포함한 가중치를 생성하고, 이를 다시 프루닝하여 client에게 전달해서, local sparse model을 생성하여 local trends를 포착한다.
모델 성능을 향상시키기 위해, 이 두 유형의 complement sparsification model은 각 round에서 dense 모델르 aggregated되며, 이는 반복적인 과정을 통해서 pruning 된다.
논문의 저자들은 CS가 FL의 근사치이기 때문에 잘 동작할 수 있다는 것을 보였고, 두가지 FL 벤치마크 데이터셋을 이용해서 CS를 실험적으로 평가했다.
CS는 vanila FL보다 client, server에서 더 적은 overhead로 비슷한 성능을 달성하였으며, FL을 위한 pruning 방법 baseline보다는 더 좋은 성능을 달성할 수 있었다.
Introduction
FL에서는 computation and communication overhead를 줄이고, model performance는 유지하는 것이 중요하다.
하지만, pruning을 communication-computation efficient하게 FL에 적용하는 게 어렵다.
pruning mechanism은 크게 3가지의 stages로 나눌 수 있다.
- Training (a dense model)
- Removing weights
- Fine-tuning
FL에서는 server에 전체 데이터가 존재하지 않기 때문에, 위 Removing->Finetuning을 server에서 할 수 없다.
그러므로, FL에서 pruning은 server와 client가 협력해야한다. 하지만 이런경우에는 communication cost는 sparsity로 인해 더 낮아지지만, client에 상당한 computation overhead가 발생하게 된다.
Communication-computation efficient model pruning for FL을 만들기 위해서는, 4가지의 요구사항이 만족되어야 한다.
- Client -> Server로 보낼때 local update의 크기를 줄여야 한다. (local 데이터로 학습한 network의 파라미터)
- Server -> Client로 보낼때 global update의 크기를 줄여야 한다. (client에게 받은 network를 활용한 global parameter)
- Client에서 pruning computation overhead를 줄여야한다.
- vanila FL에서 dense model의 성능과 유사한 성능을 달성해야한다.
또한 위의 4가지의 요구사항은 모두 "서버는 client의 data에 접근할 수 없다"는 가정을 만족해야한다.
기존 연구들은 client에 computation ovehead를 주거나, client -> server의 communication cost만 신경썼다.
이 논문에서는 위 요구사항 모두를 만족하는 Complement Sparsification(CS)를 제안했다.
메인 아이디어는, server와 client가 모두 sparse model을 생성하고 상호보완적으로 교환하는 것이다. (finetuning이 없다)
처음 rounds는 vanilla FL로 시작한다. (client가 dense를 학습하고 server는 이를 aggreate함)
그후, server는 aggregated model을 magnitude pruning으로 pruning하여 global sparse model로 만들고, 이 모델을 client에게 전달한다.
그 이후 rounds에서는 각 client가 받은 global sparse model을 dense로 학습하고, global sparse model이 0이었던 부분만 서버에게 전달한다.
서버는 해당 weight를 기존 weight와 aggregate하고 다시 프루닝을 하며, rounds를 반복한다.
이렇게 새로운 global sparse model은 client의 weight가 aggregate되어 다른 weight를 능가하기 때문에, 언젠가 모델의 모든 가중치는 학습하게 된다고 한다.
( 이해한바로는 0인 부분을 aggregate하면서, 해당 weight가 활성화되고 이는 기존에 살아있던 weight보다 더 큰 magnitude를 갖게 되며, 이런 경우에 global sparse model의 mask가 변경되면서, 최종적으로는 모든 weight가 학습이 가능하게 된다는 의미로 이해했다.)
Complement Sparsification in FL
결국 저자들이 하고자 하는건, bidirectional communication overhead를 server <-> client할때 sprase model을 보내면서 줄여주고, client에서 학습된 weight로 aggregate해가면서 weight를 finetuning하여 computation cost(별도의 fine-tuning step을 두지 않음)을 유지시키는 것이다.

방법에 대한건 위에서 다 소개한 것 같고, 그림으로 보는게 제일 쉽다. 저 rounds가 반복된다.
FL의 formulation은 아래와 같다.

client $n$의 loss $F_{n}$를 client가 갖고 있는 data의 비율만큼 곱해서 다 더하면, global empirical loss $F(w)$를 만들 수 있다.

$\theta$는 현재 local model이고, $w_{t}$는 이전 round의 global model이다. $g_{n}$은 $w_{t}$의 local data에 대한 gradient의 평균이다.
논문의 저자들은 모든 client가 모든 round에 참여하는 것을 가정했다고 한다.

위 두 식은 $\theta_{t+1}$ 이 식으로 인해 동일하다고 한다. $g_{n}$자리에 넣어보면 된다.
위는 client의 학습결과물을 aggregate하는 방법이다. 이때 learning rate는 client와 server가 달라도 무방하다.

Technical Insights
FL에서는, client는 local data를 잘 맞추는 모델을 생성하고 server는 client 모델의 noise를 평균내어 global data를 잘 맞추는 모델을 생성한다.
매 라운드마다 client는 global model을 변형해서 local data 분포를 더 따르게 학습하고, server는 client model을 조정하여 global data 분포를 포착한다.
CS에서도 이러한 특징을 이용한다.
server에서 aggregate된 dense모델에서 sparse model을 추출하는데, 이 sparse model은 global data 분포를 갖고 있다.
server는 이 sparse model을 fine-tuning하지 않지만, client에서 local data의 분포로 학습하고, 이러한 학습은 global sparse model에서 0인 부분에 더 많이 반영된다고 한다.
따라서, 이렇게 0인 부분에 local data 분포를 반영한 weight를 다시 서버에 전송하며, 이러한 효과는 global sparse model의 non-zero weight가 overfitting되는 것을 방지해주는 역할도 한다고 한다.
시간이 지나면서, 모든 weight가 학습되도록 하기 위해서, 매 round마다 fully dense model을 생성하고, 이전 round와 다른 pruning mask를 생성해야한다. 이는 round $t+1$에서 client에서 받은 weight를 round $t$와 합치면서 해결하고, 더 확실하게 하기 위해서 이전 $t$에서 pruning된 가중치가 더 크게 학습되도록 하기 위해서 aggregate ratio $\eta'$를 1보다 큰 값을 사용하여 중복 pruning을 방지한다고 한다.
이때, 더 큰 값을 사용할수도 있지만, gradient explosion을 방지하기 위해서 $1/\eta$보다는 작아야한다고 한다.
Algorithm Analysis
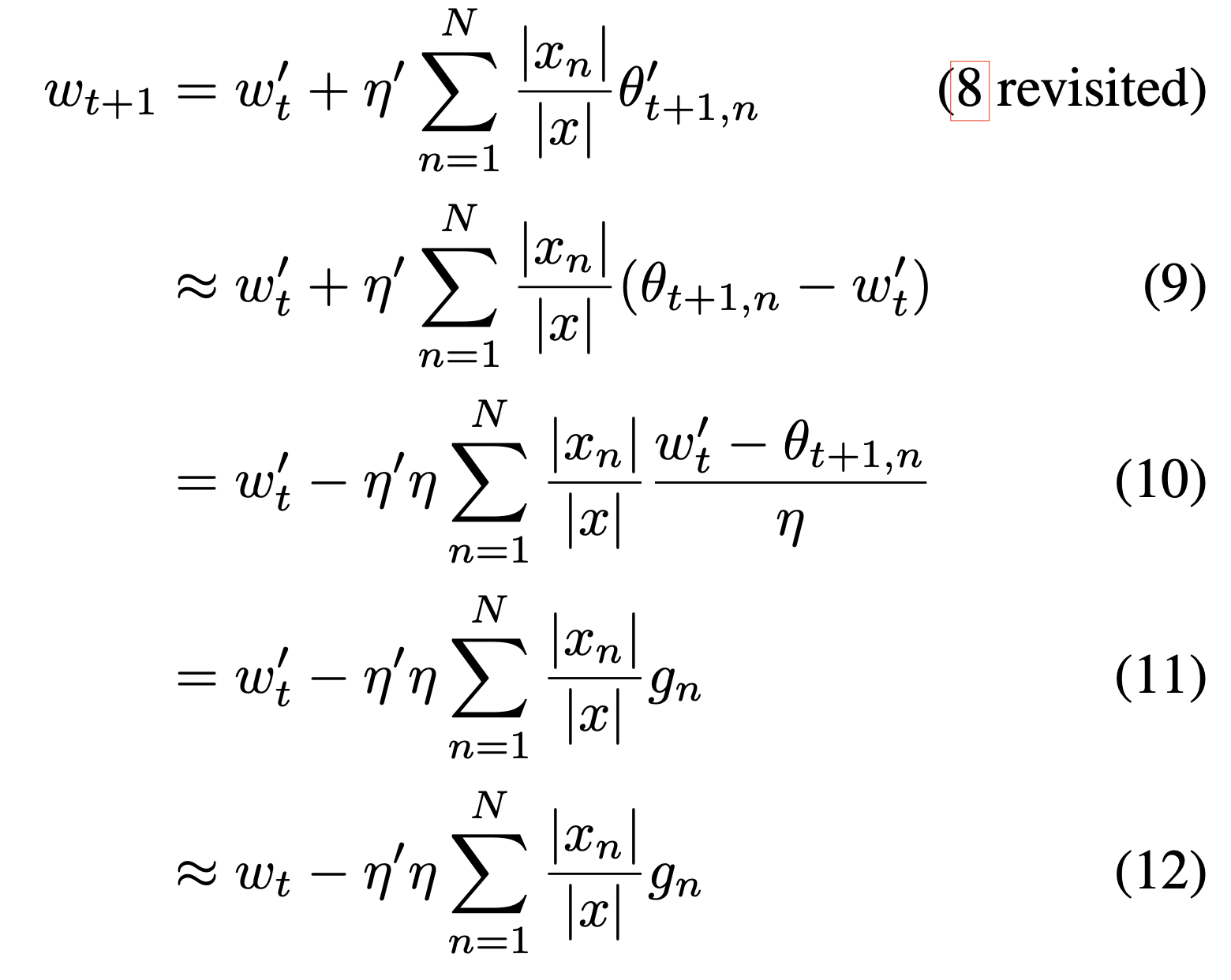
Experiments
LEAF, FEMNIST 두개를 사용했으며, non-IID를 사용해서 sampling했다.
LEAF를 위한 모델은 sentiment analysis model로 pretrained BistillBERT를 사용하고, 2개의 fc(32 / 3), 마지막 ReLu, softmax를 사용했다.
FEMNIST를 위한 CNN은 3개의 3x3, stride1 conv-net을 사용했다. (32 / 64/ 64) 사이사이엔 ReLU를 넣었고 max pooling은 처음과 마지막 conv에 넣었다. 그러고 flatten해서 (100 / 62) fc에 넣었다. relu와 softmax를 각각 사용했다.
P100x4ea로 총 64GB를 사용했다.
$\eta'$은 1.5로 세팅하고 server의 pruning sparsity는 50%를 사용했다.
Baselines
PQSU (https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9366879) IEEE Access
- structured pruning, weight quantization, selective updating
PruneFL (https://arxiv.org/pdf/1909.12326) IEEE TNNLS
- initial pruning at a selected client, pruning during FL, adapats model size to minimize the training time
baseline이 좀 부실해보이긴 하다.
Results
CS vs vanilla FL
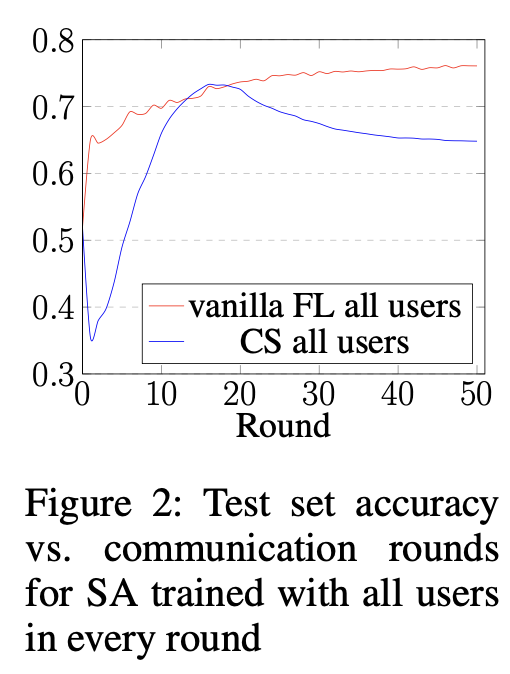
그림 2를 보면, 초반에는 pruning으로 인한 acc gap이 있다.
하지만, FL이 진행되면서, CS는 finetuning 효과를 확실하게 보여주며, overfitting되기 전까지 vanilla와의 성능 폭을 줄여주는 것을 볼 수 있다. (best model을 inference에서 사용할 수 있기 때문에 상관없다고 주장한다.) (73.3%, 76.1%)
* val acc도 아니고, test acc로 best model을 만들어서 inference가 가능하다? 이건 치팅아닌가...?

위 그림 3은 10개의 random user를 선택했을때의 round별 acc이다.
best acc기준으로 vanilla 성능과 유사한 수준을 달성했다고 한다. (74.3%, 76.9%)
또한, CS가 vanilla보다 안정성이 높다고 하는데, 이는 CS가 non-IID data의 효과를 완화시키기 때문이라고 한다.
마찬가지로, Image Classification과 Zoom 데이터셋에서도 성능이 높다는 것을 보였다.
그림 3에서 baseline과 비교했을때처럼 PruneFL, PQSU는 각각 71.5%, 73.4% acc로 2.8%, 0.9%정도 CS보다 낮은 정확도를 보였다. 좀 더 큰 FEMNIST dataset에서는 17%, 15%가 낮은 acc를 보였다.
Global sparse model vs. aggregated dense model
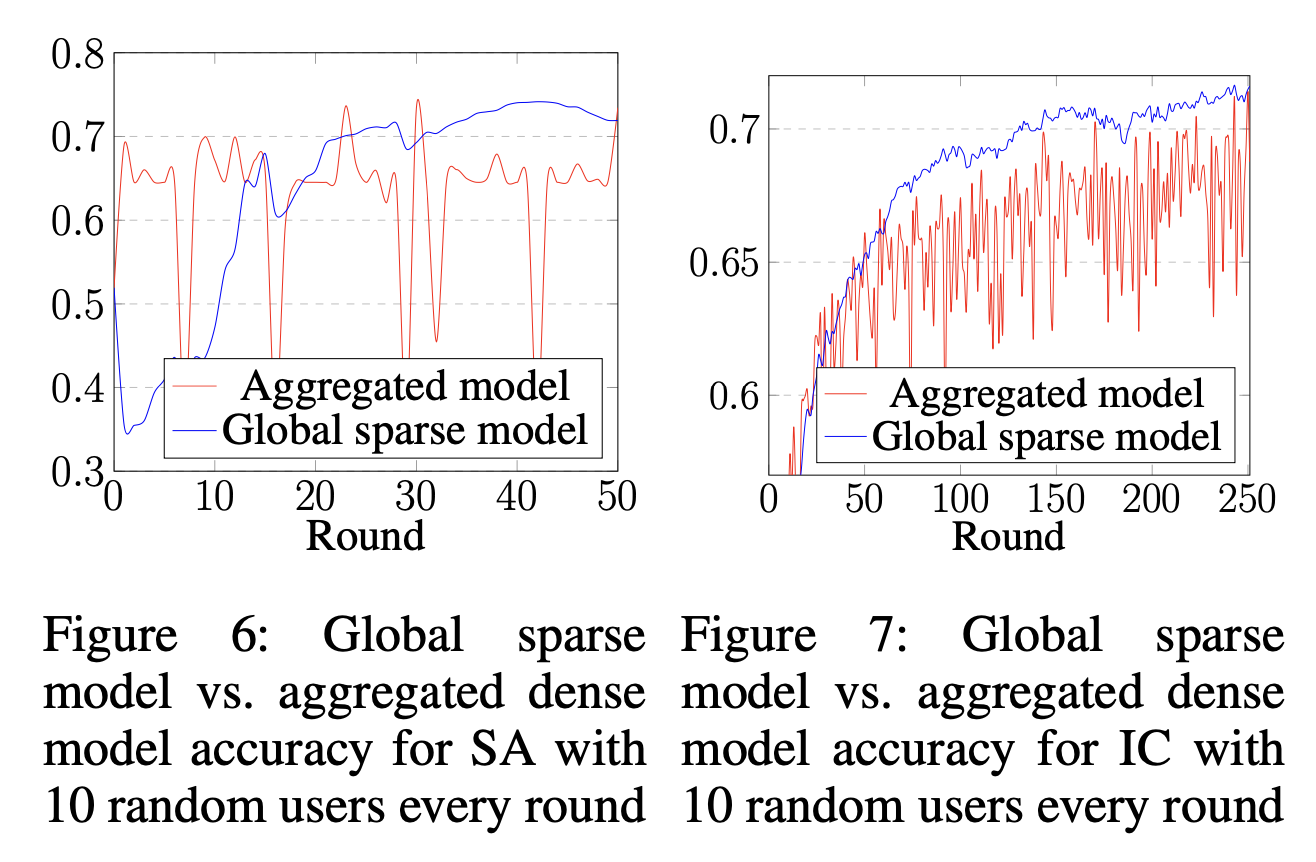
Global Sparse model과 dense model을 비교한 그림이다. (매 round에서 pruning전과 비교하는 것)
전반적으로, global sparse model이 좀 더 smooth한 그래프를 보이며, aggregated model의 acc를 넘는다.
이를 통해 CS가 communication overhead와 good model performance를 챙길 수 있음을 보였다.
저자들은 dense model이 global distribution과 noisy distribution shift를 모두 포착하기 때문이라고 이야기한다.
각 라운드에서 low magnitude로 프루닝하면서, 이 noise distribution shift를 제거하여, global distribution을 더욱 잘 학습할 수 있었다고 이야기한다.
Client model sparsity
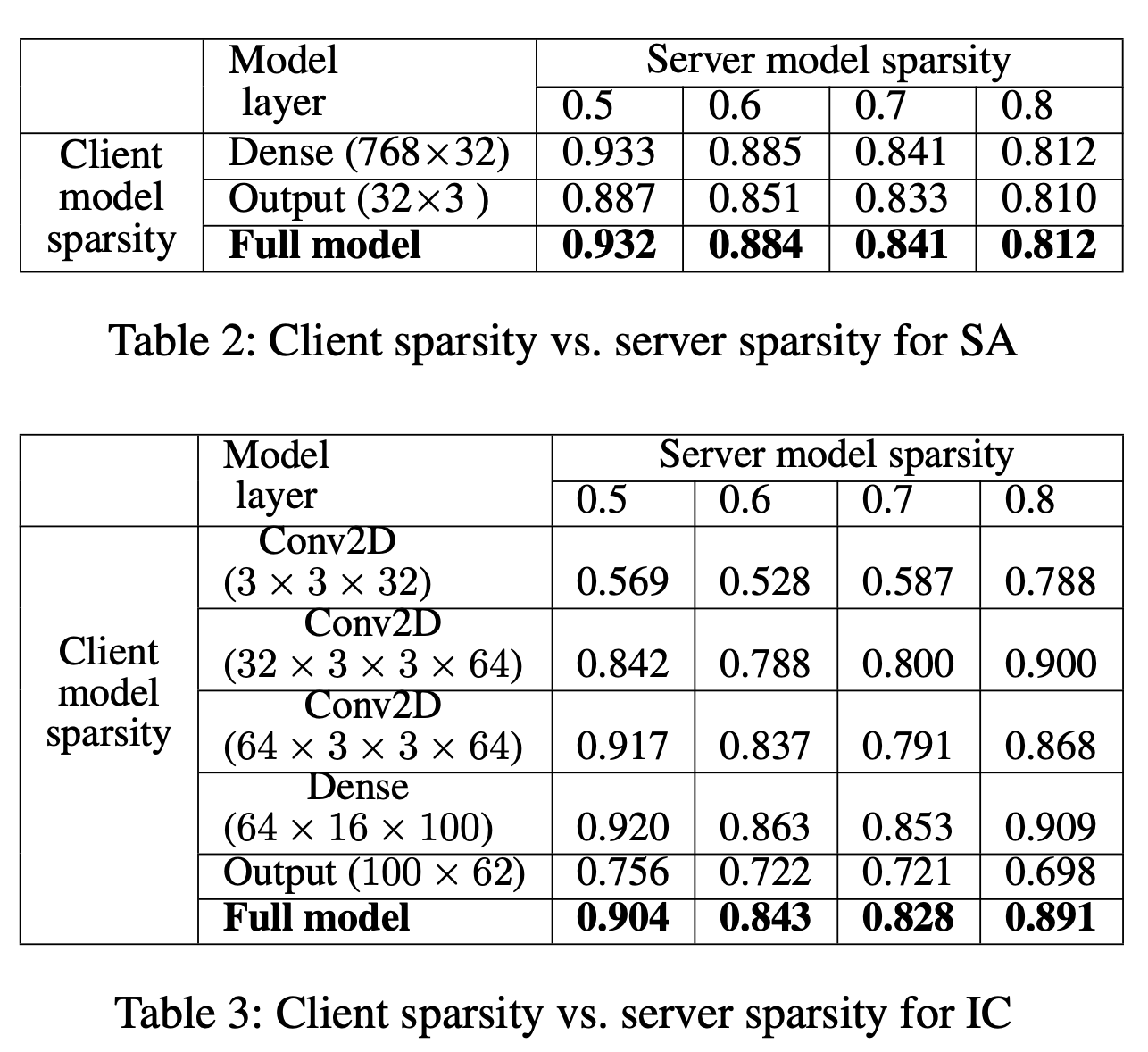
client sparsity는 client -> server의 communication cost 감소를 나타내고
server sparsity는 server -> client의 communication cost 감소를 나타낸다고 한다.
(masks는 작아서 계산하지 않았다고 한다.)
위 table들은 server가 특정 sparsity를 갖고 있을때, client의 sparsity를 나타낸다고 한다.
음.. 근데, server의 sparsity가 높으면 server -> client의 cost가 낮아지는건 이해했다. 근데, server의 sparsity가 높을수록 client->server의 cost가 높아지는 거 아닌가. 물론 dense보단 작겠지만
Training FLOPs savings
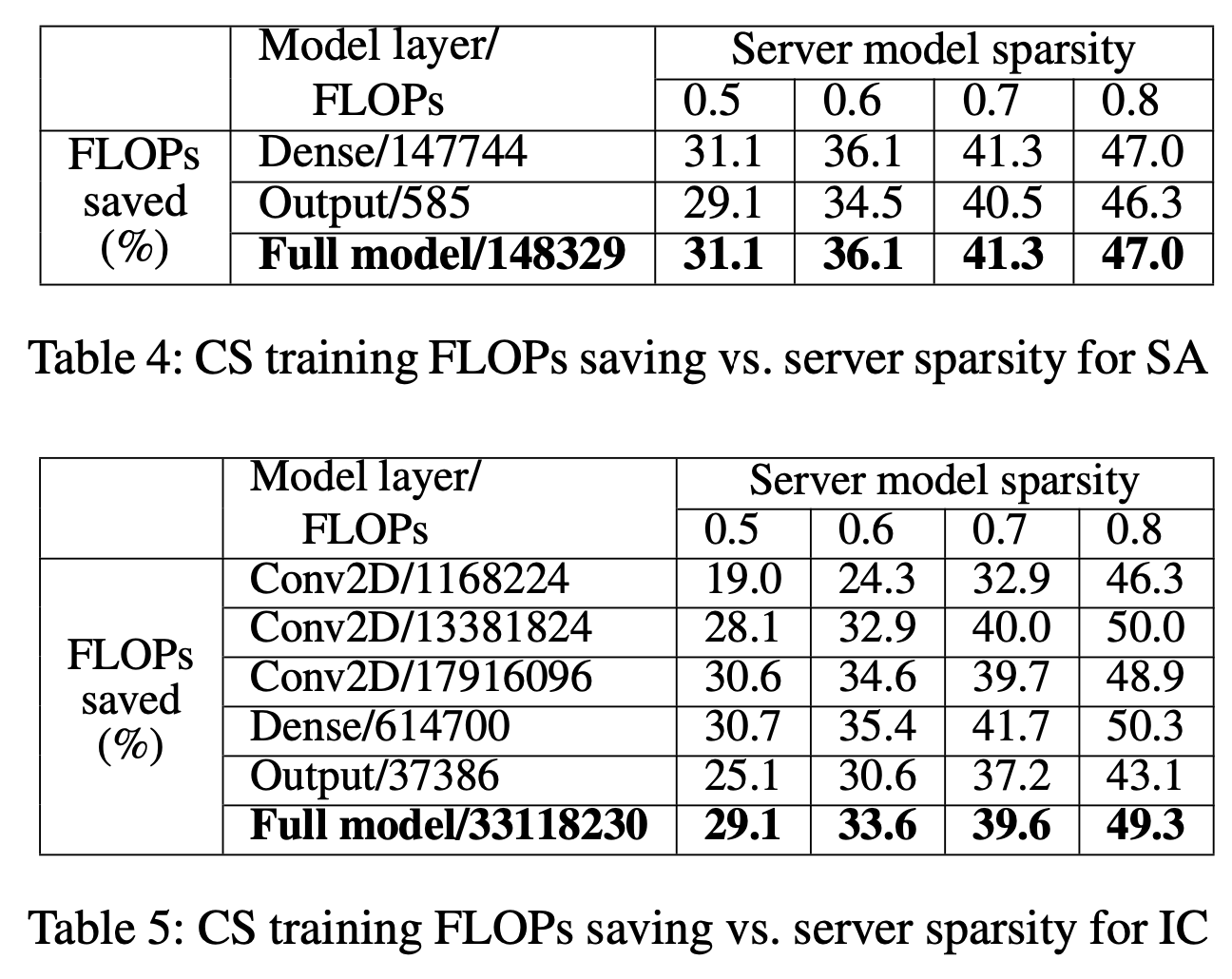
client의 computation overhead를 계산하기 위해, training cost를 측정했다고 한다.
forwarding에서는 FLOPs를 측정했고, backward에서는 MAC를 측정했다고 한다.
- 현대 하드웨어는 tensor를 연산할때 ax+b(FMA)라는 명령어셋을 호출하는데, 이 명령어셋이 몇번이 호출되었는지를 측정하는게 MAC라고 한다.
- FLOPs는 곱셈과 덧셈을 따로 보기 때문에, MAC의 두배이다.
Forward에서는 client가 server로부터 받은 0이 아닌 weight에 대해서 FLOPs를 계산하고, Backward에서는 hidden state와 derivative에 대해서 MAC으로 계산했다.
간단리뷰
저자들은 서버에서 죽은 weight를 각 local data로 학습한 client에서 받아와 aggregate하는 방법을 제안했다.
이러한 과정을 통해서 finetuning이 필요없는 FL에서 사용가능한 새로운 프루닝 방법을 제안했다.
이 방법은 communication cost와 client단에서의 computation cost를 모두 감소시킬 수 있었고, dense와 유사한 성능을 낼 수 있었다.
'Papers > Compression' 카테고리의 다른 글
| Learned step size quantization (1) | 2024.09.10 |
|---|---|
| DaFKD: Domain-aware Federated Knowledge Distillation (0) | 2024.07.31 |
| Sparse Weight Averaging with Multiple Particles for Iterative Magnitude Pruning (0) | 2024.06.25 |
| SPARSE MODEL SOUPS: A RECIPE FOR IMPROVED PRUNING VIA MODEL AVERAGING (0) | 2024.06.11 |
| Fantastic Weights and How to Find Them: Where to Prune in Dynamic Sparse Training (0) | 2024.06.07 |



