
둔비의 공부공간
Sparse Weight Averaging with Multiple Particles for Iterative Magnitude Pruning 본문
Sparse Weight Averaging with Multiple Particles for Iterative Magnitude Pruning
Doonby 2024. 6. 25. 01:50https://openreview.net/forum?id=Y9t7MqZtCR
Sparse Weight Averaging with Multiple Particles for Iterative...
Given the ever-increasing size of modern neural networks, the significance of sparse architectures has surged due to their accelerated inference speeds and minimal memory demands. When it comes to...
openreview.net
(재구현이 되는지는 검증하지 못했는데, 위 링크에 zip파일에 보면 코드도 올라와있다.)
Abstract
IMP(Iterative Magnitude Pruning)은 여전히 state-of-the-art 알고리즘으로 사용되고 있다.
최근 두가지 성공적인 IMP solutions이 선형적으로 loss barrier없이 연결된다는 발견을 토대로, 논문의 저자들은 Sparse Weight Averaging with Multiple Particles(SWAMP)을 제안했다.
SWAMP란, IMP를 간단하게 변형해서 IMP solution을 앙상블한 것보다 더 좋은 성능을 달성했다.
매 iteration마다, 다른 batch 순서지만 동일한 mask를 사용하는 여럿 sparse model을 학습하고, avg하면서 하나의 single mask를 만든다.
Introduction
Lottery Tickets에 따르면, 초기화할때부터 dense의 성능을 낼 수 있는 subnetwork가 존재한다고 했다.
이러한 matching subnetwork는 IMP와 Rewinding(링크)을 통해서 찾을 수 있으며, 이 방법은 3가지의 단계로 구성된다.
1. network를 일정 횟수 학습시킨다.
2. 가장 작은 크기의 weight를 프루닝한다.
3. 가중치를 초기 iteration으로 돌리고, 프루닝된 가중치는 0으로 고정한다.
이 과정을 여러번 반복하면, 최종적으로 rewinding된 subnetwork는 dense와 맞먹는 matching ticket이 된다고 한다.
IMP는 특히, 엄청 높은 sparsity에서 좋은 성능을 달성할 수 있다고 한다.
근데, IMP의 단순한 방법을 생각했을때엔 좋은 성능을 낼 수 있는 것이 조금 역설적인데, 최근 연구에서는 lottery ticket 가설과 linear mode connectivity 사이의 연관성을 분석하여, IMP의 효과가 stochastic optimization 안정성에 의존한다는 것을 밝혔다. (동일한 loss landscape에 존재한다?)
Paul (2023) 에서는 서로 다른 sparsity를 갖는 연속적인 IMP 솔루션간에서도 linear mode connectivity가 존재한다는 것을 찾았다. 이는 IMP가 연속적인 라운드에서 솔루션이 분리된 경우, matching network를 찾는 것에 실패하기 때문에, pruning ratio와 rewinding 반복이 IMP 솔루션간의 connectivity를 유지하는데 중요하다고 이야기했다.
이러한 IMP와 Linear mode connectivity에 연관성에서, 논문의 저자들은 loss landscape perspective로 확장해서 이해했다고 한다.
- 경험적으로 같은 ticket이지만, 여러 SGD 노이즈로 학습된 모델은 weight-average가 가능하다는 것을 입증했다. 이러한 weight average는 flat minima로 이끌어서, 더 좋은 일반화 성능을 달성할 수 있도록 한다.
- 위와 같은 관찰로, SWAMP라는 새로운 iterative pruning technique를 제안한다. SWAMP는 IMP 성공에 기여하는 중요한 특징인 linear connectivity가 유지된다는 것을 확인했다.
- 여러 실험을 통해, SWAMP 알고리즘이 다른 baseline보다 우수하다는 것을 경험적으로 입증했다.
SPARSE WEIGHT AVERAGING WITH MULTIPLE PARTICLES (SWAMP)
IMP: A LOSS LANDSCAPE PERSPECTIVE
Matching ticket은 SGD noise $\xi$의 안정성에 영향을 크게 받는다고 입증되어졌다.
(만약 동일한 random initizalization $w_{0}$로 두 모델을 학습해도, 다른 SGD noise $\xi^{(1)}$, $\xi^{(2)}$로 인해서 SGD로 학습된 solutions간의 linear connectivity가 방해된다고 한다.
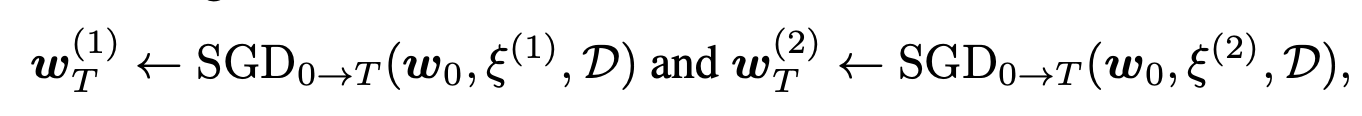
또한, IMP로 얻은 sparse solution도 SGD noise에 안정적일때만 matching이 된다는 것을 실험적으로 입증했다.
이러한 안정성을 보장하는 방법은 optimization trajectory의 초기 phase를 공유하는 것이라고 한다.
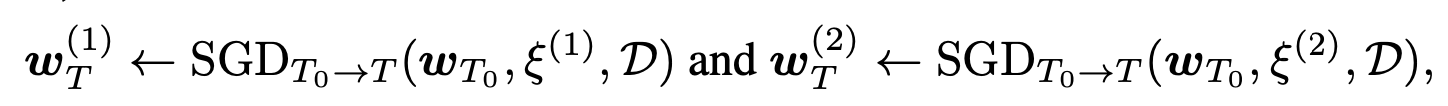
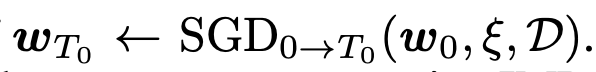
최근에는 sparsity가 다른 IMP solution간에서도 linear connectivity가 있음을 확인했으며, 이것이 IMP의 성공요인이라고 이야기하는 논문도 있다.
SWAMP: AN ALGORITHM
위에서 이야기한 matching ticket의 안정성에서 영감을 받아서, 논문의 저자들은 SWAMP를 IMP를 위한 tailored sparse weight averaging technique을 제안했다.
SWAMP는 기존 IMP와 두가지 측면에서 다르다고 이야기한다.
1. matching tickets을 여러번 복사해서 사용하고, 이를 다른 random seed로 학습한다.
2. SGD를 SWA로 대체한다. SWA는 학습 경로의 부분집합을 주기적으로 샘플링하여, 파라미터의 이동평균을 구하는 방법이다. 다음 프루닝 step전에 이 부분집합들을 평균내서 사용한다.

SWAMP: A LOSS LANDSCAPE PERSPECTIVE
위에서 언급했던 IMP의 특성이 SWAMP에도 적용되는지 분석한 부분이다.
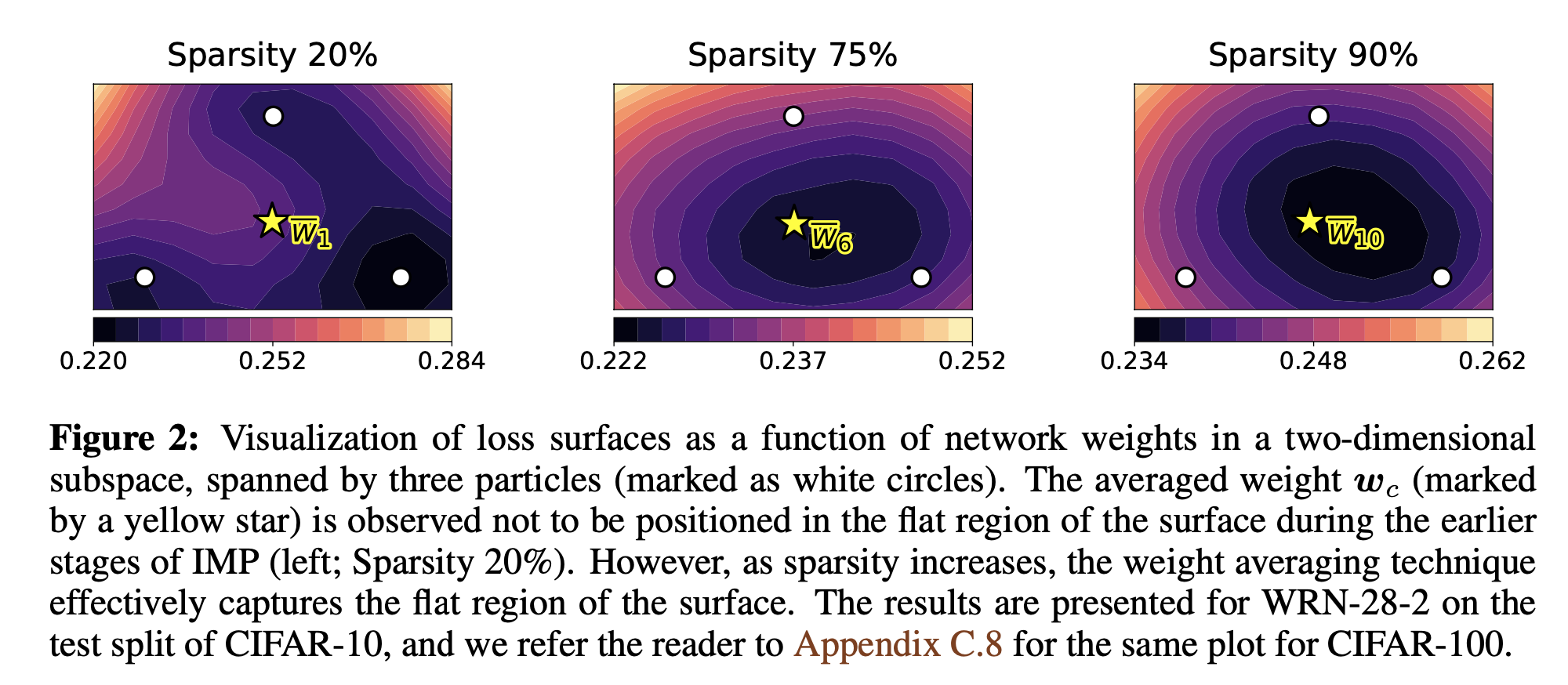
위 그림을 보면, IMP로 학습된 particles와 weight avg의 particles의 loss surface를 시각화한 것이다.
초반(sparsity 20%)에서는 loss landscape가 non-convex해서 weight avg가 실패했지만, sparsity가 증가하면서 loss surface가 convex해지면서 particles가 동일한 넓은 곳에 위치하면서 weight avg가 잘 되는 것을 볼 수 있다. 이는 이전 연구에서 작은 네트워크일수록 low-loss curve를 찾기가 쉽다는 것과 일치한다고 한다.(sparsity가 커졌다 -> network가 작아졌다 -> low-loss curve를 찾았다)
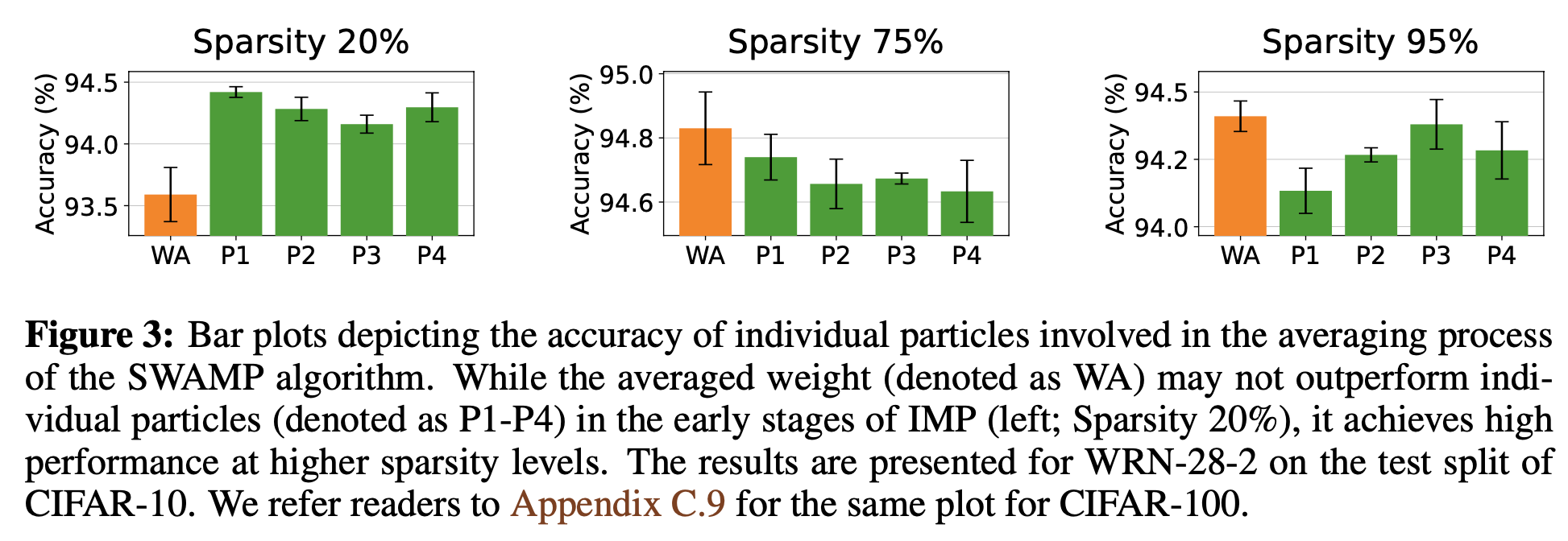
위 그림에서 보면, Particle1, 2, 3, 4보다 weight avg가 high sparsity에서 우수함을 확인할 수 있다.
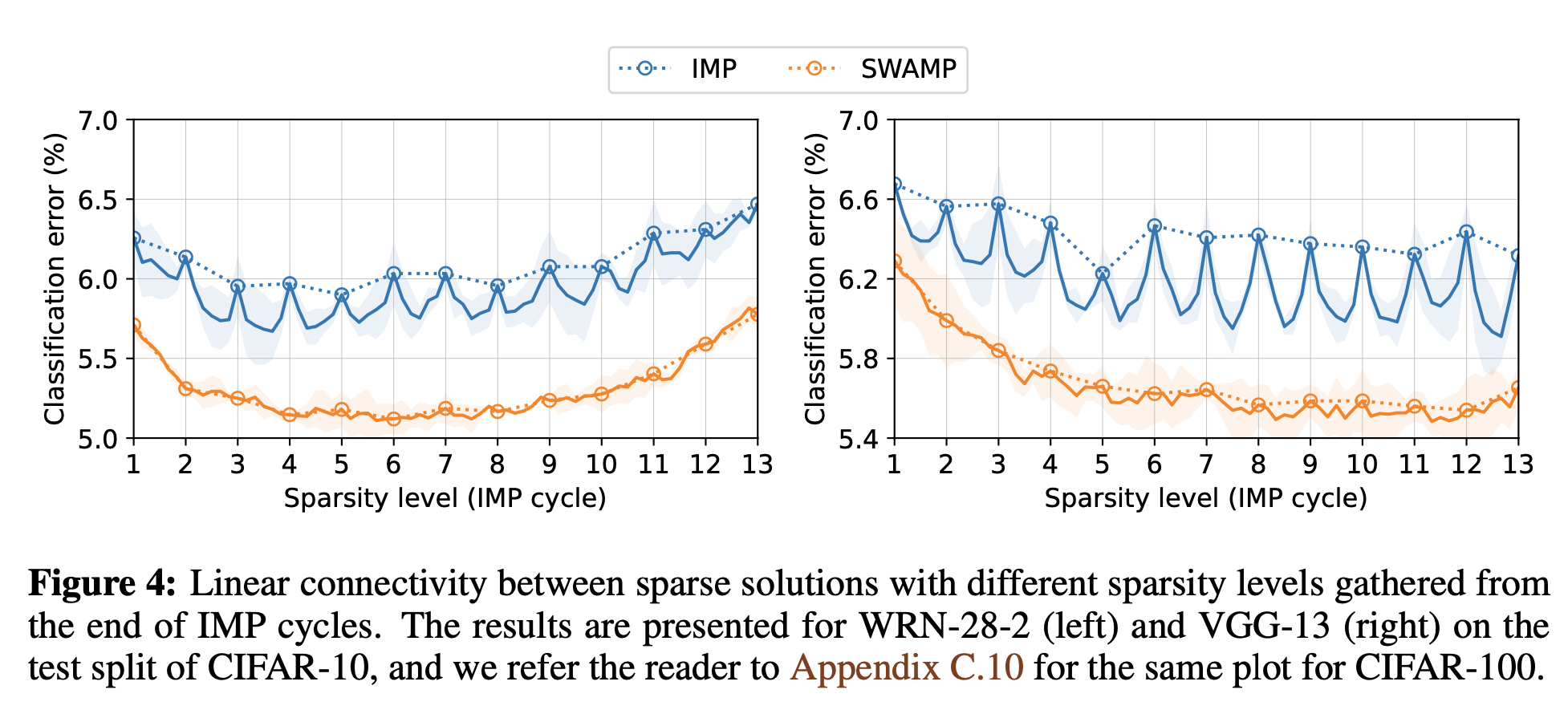
또한, 위 그림4에서 Sparsity level이 증가하여도 SWAMP는 안정적인 추이를 보이므로, SWAMP의 연속 solution이 linear connectivity하다고 이야기한다. (안정성이 높다고 이야기하는 듯 하다)
Experiments




위 Table4는, 두가지 측면에서 SWAMP의 효율성을 측정한 것이다.
1. Mask generation
2. Sparse training
초기 iteration을 제외하고(low sparsity) 모두 vanilla SGD optimization보다 높은 성능을 달성했다.
'Papers > Compression' 카테고리의 다른 글
| DaFKD: Domain-aware Federated Knowledge Distillation (0) | 2024.07.31 |
|---|---|
| Complement Sparsification: Low-Overhead Model Pruning for Federated Learning (0) | 2024.07.09 |
| SPARSE MODEL SOUPS: A RECIPE FOR IMPROVED PRUNING VIA MODEL AVERAGING (0) | 2024.06.11 |
| Fantastic Weights and How to Find Them: Where to Prune in Dynamic Sparse Training (0) | 2024.06.07 |
| Scale Decoupled Distillation (0) | 2024.05.16 |



