
둔비의 공부공간
SPARSE MODEL SOUPS: A RECIPE FOR IMPROVED PRUNING VIA MODEL AVERAGING 본문
SPARSE MODEL SOUPS: A RECIPE FOR IMPROVED PRUNING VIA MODEL AVERAGING
Doonby 2024. 6. 11. 12:38https://github.com/ZIB-IOL/SMS
GitHub - ZIB-IOL/SMS: Code to reproduce the experiments of the ICLR24-paper: "Sparse Model Soups: A Recipe for Improved Pruning
Code to reproduce the experiments of the ICLR24-paper: "Sparse Model Soups: A Recipe for Improved Pruning via Model Averaging" - ZIB-IOL/SMS
github.com
https://arxiv.org/abs/2306.16788
Sparse Model Soups: A Recipe for Improved Pruning via Model Averaging
Neural networks can be significantly compressed by pruning, yielding sparse models with reduced storage and computational demands while preserving predictive performance. Model soups (Wortsman et al., 2022) enhance generalization and out-of-distribution (O
arxiv.org
Abstract
Model soups[Link]이 inference time을 증가시키지 않고, 여러 모델의 파라미터를 평균내어 하나의 모델로 만들어 사용함으로써, 일반화성능이랑 OOD 성능을 강화시킬 수 있음을 보여줬다.
그러나, sparsity와 parameter averaging을 둘 다 챙기기는 어렵다. (model의 sparse connectivity가 각자 다르기 때문에, 단순하게 avg하게 되면 전체적인 sparsity가 떨어지기 때문이다)
이 논문은 이러한 문제를 IMP의 single retraining phase에서 진행하면서 이를 해결했다. (batch ordering이나 weight decay가 다르고 sparse connectivy는 동일하다.)
이렇게 설계한 모델을 averaging함으로써, generalization과 OOD performance를 향상시킬 수 있었다.
Contributions
- 논문의 저자들은 잘 훈련된 모델을 pruning하고, batch order, weight decay, retraining phase 같은 다양한 하이퍼파라미터로 여러 모델을 훈련하면, 일반화 성능과 OOD 성능이 모두 향상된 avgeraging하기 좋은 모델을 생성할 수 있음을 보였다. 이때, 이러한 모델들이 부모 모델의 sparse pattern이 유지된다.
- SMS라는 pruning-retraining phase를 averaging model에서 시작하는 새로운 아이디어를 제안했다. SMS는 평균 모델이 단일 모델보다 일반화 및 OOD 성능이 우수하고, 평균에서 retraining된 모델이, 단일 모델에서 retraining한 모델보다 더 좋은 성능을 보이는 것을 확인했다.
- SMS의 효과를 입증하기 위해, 다른 SOTA와 결합하여, pruning during training domain에서 상당한 성능 향상을 보였다.
Methods
최근 transfer learning domain 연구[Link1] [Link2] 에서 영감을 받았다. (same pretrained model에서 fine-tuning한 모델은 동일한 loss basin을 갖고, 이는 soup로 combined가 가능하다는 연구).
논문의 저자들은 이러한 특성을 pruned model에서 retraining phase에서도 달성할 수 있지 않을까? 했다.
(transfer learning과 IMP의 single phase의 유사성을 보았다고 한다. source domain -> target domain으로 전환할때의 optimization objective가 변경되어 adaptation이 필요한 것 처럼, pruning도 loss가 갑자기 변하며, 새로운 sparse 환경에 적응이 필요하다)

위 그림의 왼쪽 single phase를 보면, pretrained model's weight $\theta$를 pruning하여 $\theta_{p}$를 만들고 $m$번 복제한다. 복제된 $m$ 모델을 서로 다른 hyperparameter config(random seed, weight decay factors, retraining length, learning rate schedule) 로 retraining을 한다.
이후, 독립적으로 학습된 $m$개의 모델을 하나의 $\theta_{avg}$로 합친다. 이 과정은 모든 $m$개의 모델 $\theta_{1}$, $\theta_{2}$, $\theta_{m}$ 모델이 모두 동일한 sparse pattern을 공유하도록 보장된다.
SMS의 장점은 $m$의 수와 무관하게 inference complexity는 동일하게 유지되고, $m$개의 모델을 retraining하는 과정은 완전하게 병렬화될 수 있다고 한다. 각 단계에서 이전 단계의 $\theta_{avg}$를 사용하면서, sparse pattern이 유지되고, 사이클 수가 증가함에 따라서 IMP의 특성상 더욱 희소해져, 추가적인 효율성 향상이 가능할 수 있다고 주장한다. 또한, SMS는 large pretrained model의 이점을 활용하면서도, 처음부터 훈련할 필요가 없다고 이야기한다.
모델을 효과적으로 합치는 것도 어려운 문제인데 (모델들이 서로 멀리 떨어져있을 수 있다고 이야기하는데, 아마 loss landscape의 basin상의 거리를 말하는 것 같다.), 이를 해결하기 위해 UniformSoup와 GreedySoup를 사용했다고 한다.
- UniformSoup : 각 모델에 $1/m$을 부여하여 합치는 방법
- GreedySoup : validation accuracy로 정렬하고, 검증 정확도가 향상될때만 모델을 합치는 방법
Experiments
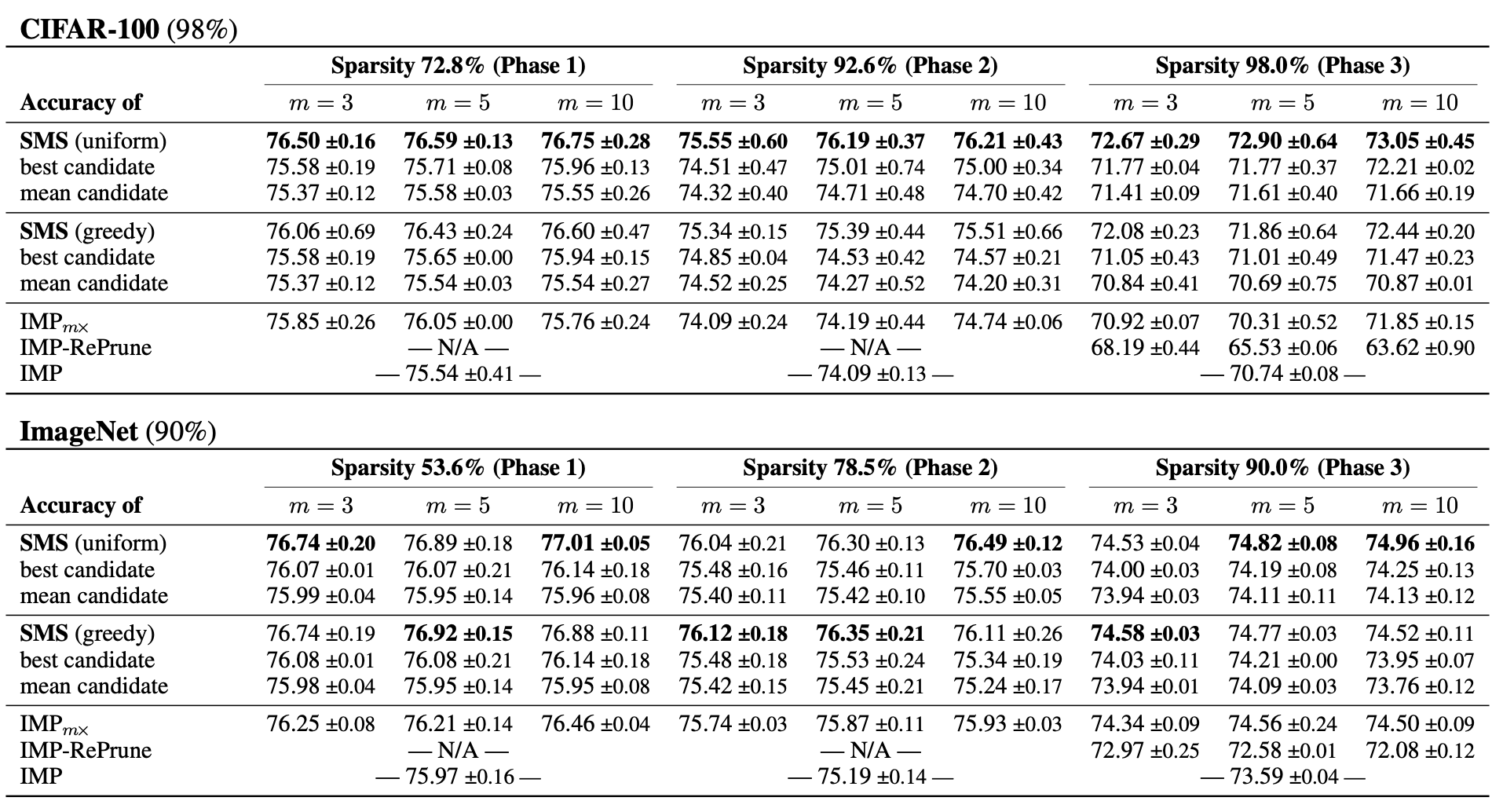
각 phase에서 제일 좋은 단일 모델 (best candidate)와 phase에서 단일 모델의 평균 (mean candidate), IMP($m=1$)과 비교했다.
IMP는 soup과정이 들어가지 않기 때문에, 구분하여 실험을 진행했다고 하는 것 같다.
또한 $m$이 있으니, retrain epoch가 $m$배가 커지므로, IMP$_{mx}$버전을 새로 만들어서 비교했다.
저자들은 IMP-RePrune이라는 새로운 기준을 제안했는데, IMP-RePrune은 여러 단계에서 pruning mask가 달라지는 애들을 말한다고 한다.
위 표에서는 CIFAR100+WideResNet20, ImageNet+ResNet50을 사용한 IMP-phase의 결과를 보여줬다고 한다.
ALLR과 한 phase당 10 retraining epoch을 사용했다고 한다. SMS에서는 $m$개의 모델에 대해서 random seed를 설정했으며, CIFAR100은 98% sparsity, ImageNet은 90% sparsity를 target으로 진행했다.
저자들은 위의 실험을 토대로, model soup가 개별적인 soup candidate들의 성능을 개선할 수 있으며, prune-retrained된 모델들이 평균화가 가능하며, 실질적으로 일반화 성능이 향상되는 것을 의미한다고 주장한다. 또한, CIFAR에서는 uniform이 greedy보다 좋다는 것을 알게 되었다고 한다.

위 그림을 보면, 제일 좋은건 그냥 random seed를 사용하는 것이라고 한다. 다른 하이퍼파라미터는 잘못된 값의 경우 큰 정확도 손실을 부른다고 한다.
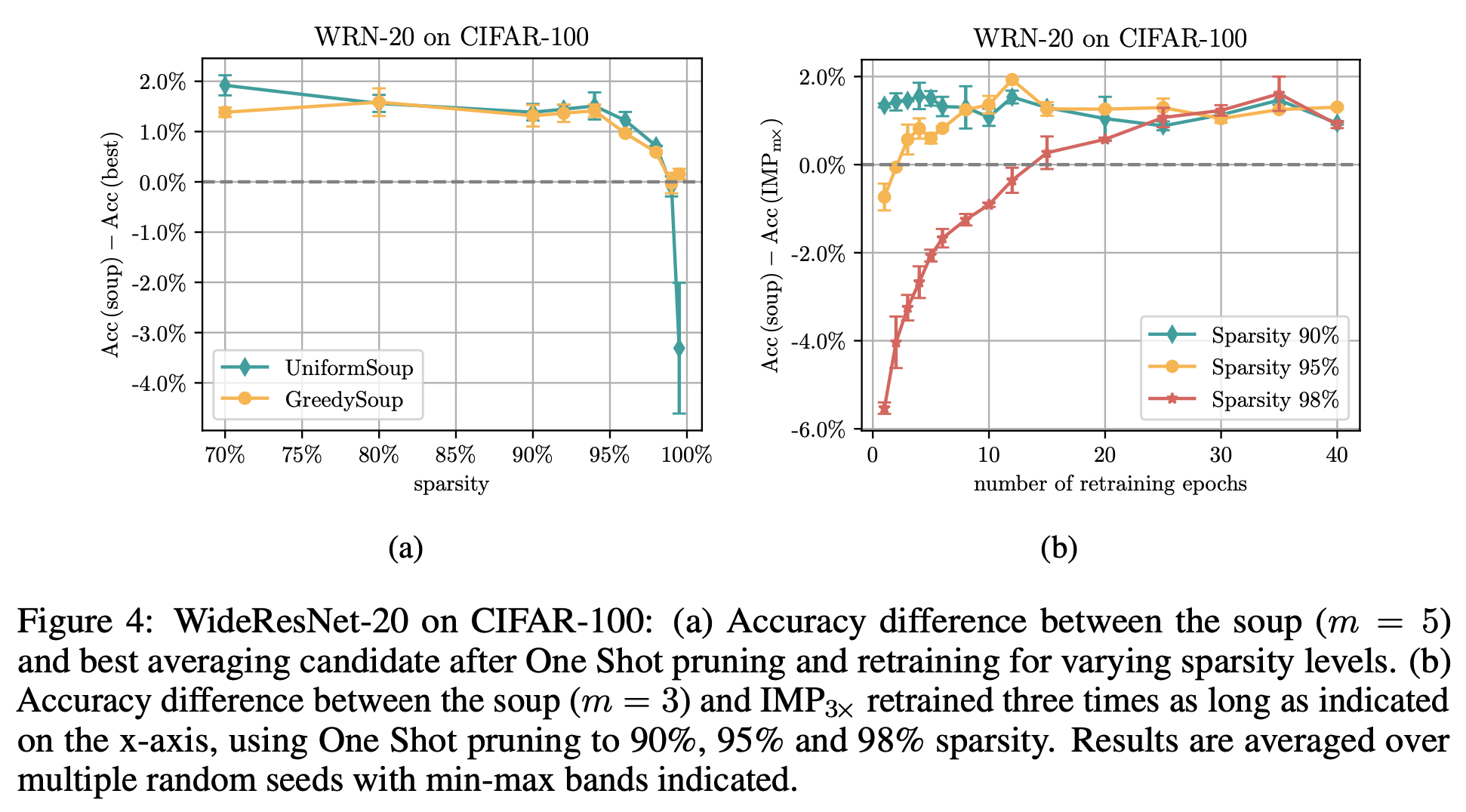
위 그림의 왼쪽(a)을 보면, $m=5$의 model soup와 다양한 sparsity에서의 best candidate의 정확도를 측정하였는데, Uniform과 Greedy 모두 일반 단일 모델보다 2%의 가까운 정확도를 향상시킬 수 있었으나, sparsity가 커지면서 점차 줄어들고 Uniform의 경우 성능이 하락하는 모습을 보인다. 저자들은 일정 sparsity 이상에서는 무작위성에 대한 안정성이 감소하여, 모델의 발산이 발생하고 모델의 평균화를 방해한다고 이야기한다.
위 그림의 오른쪽(b)을 보면, $m=3$의 model soup와 IMP$_{3x}$의 성능을 보였다.
중간 sparsity에서는 $m$모델의 avg가 단일 모델의 훈련을 $m$배 하는 것보다 좋지만, sparsity가 높을때(빨강)는 짧게 재훈련에서 avg하는 것은 단일성능보다 성능이 떨어진다. (15epoch를 기점으로 avg가 단일보다 좋다고 이야기한다.)
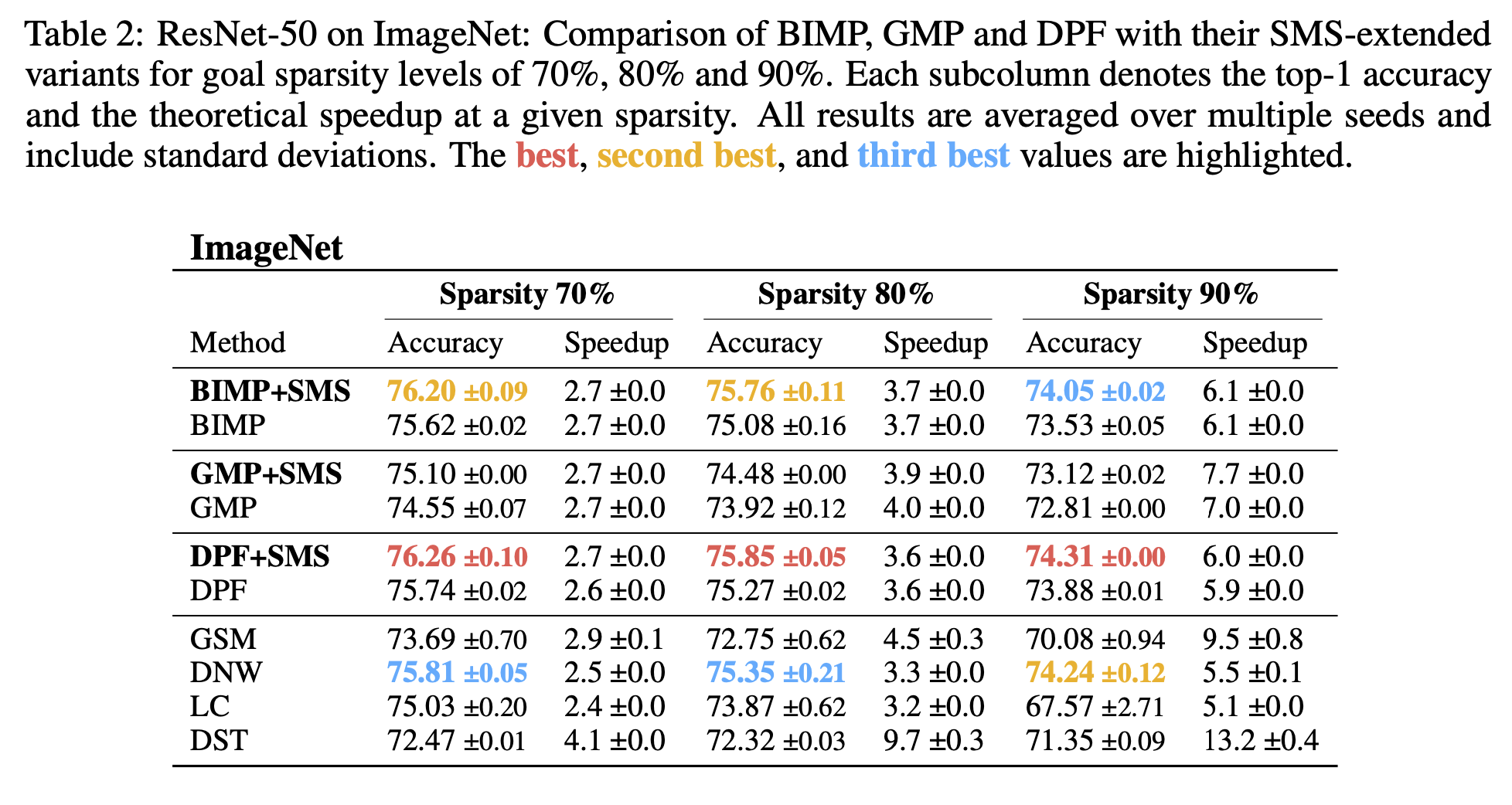
pruning mask가 변하기 전에 SMS를 적용했고, 기존 방법보다 성능을 향상시킬 수 있었다고 이야기한다.
STR같은 다른애들도 실험을 진행했는데, 잘 안되어서 제외했다고 이야기한다. BIMP는 저자들의 이전 논문중 하나이다.



